Visual Prompting for Generalized Few-shot Segmentation: A Multi-scale Approach
广义小样本学习,小样本学习的一种更现实的变体引入,允许从基类或新类中查询图像。
广义小样本分割(GFSS)任务,即利用未标记的目标图像来改进新类的分割,同时通过知识蒸馏保持基类的性能。
介绍
在自然语言处理和视觉语言领域中使用的基础模型,是基于广泛的数据集训练得到的,具有很强的泛化性,并在多种下游任务上表现出色。这些基础模型已经通过不同的提示技术调整,以便使用在小样本领域。然而,像定位(localization)、提示(prompting)这些在密集预测和语义分割任务上有助于小样本展示的技术,仍然有待探索。
小样本语义分割:目的是用很少的标记训练例子来分割新的(看不见的)类。
挑战:
- 广义小样本分割(GFSS)任务的目标是在基类和新类上都表现良好,比只关注新类上的表现更具挑战。
- 新类上的提示学习具有挑战。必须确保从少数样本中学习到的新提示与基提示有足够的区别,以避免新基类的错误分类。
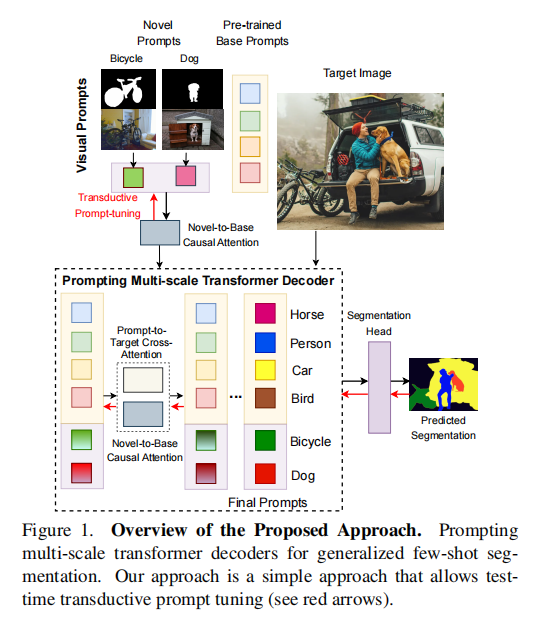
为了解决上述挑战,作者开发了一种简单而高效的transformer解码器视觉提示,用于多尺度的密集预测,它依赖于novel-to-base因果注意,而不需要元训练。作者将detr风格的架构中的查询视为一种视觉提示的形式,并设计了一种机制来初始化和学习新的提示。然后,novel-to-base的因果注意允许base提示影响novel提示表征,而不能反过来(这里的因果指的是单向性)。直观地说,这允许novel提示被排斥和/或吸引到它们的base对应物上。这种注意力是在不同尺度(转换器的层)之间共享的,因此能更稳健地学习和提高性能。提示的多尺度细化有助于在多个尺度上进行图像特征的交互和推理,从而有助于更好的密集预测。最后,作者在一个直推式设置中扩展了这种架构,在其中,novel提示和base提示都可以在测试时对无监督目标进行微调,以进一步提高性能。所提出的架构和方法如图1所示
Transductive和Inductive
- Inductive learning归纳式学习:通过已经观察到的训练数据,推理到通用的场景里面。
- Transductive learning直推式学习:通过已经观察到的训练数据以及测试数据(不知道标签),预测测试数据的标签/分类等。
区别:
在机器学习中,Inductive learning就是传统的有监督学习,通过训练数据训练的模型预测从未接触过的测试数据的标签。Transductive learning在开始的时候同时知道训练数据和测试数据,即便不知道测试数据的标签,但是能够在训练学习过程中能够利用测试数据的pattern等额外信息。
主要贡献:
- 为GFSS设计了一个多尺度的视觉提示transformer解码器架构,具有可学习的提示,允许为novel类创建novel提示,通过support image(及其掩码)的掩码平均池化(masked average pooling)进行初始化。
- 在这个架构中,提出并学习了一个在novel提示和base提示之间的多尺度的(共享的)novel-to-base的交叉注意机制。
- 提出了一种新的直推式提示调优(Transductive Prompt-tuning),它允许视觉提示在测试的(未标记的)图像上进行调优(即术语中转换的含义)。
方法
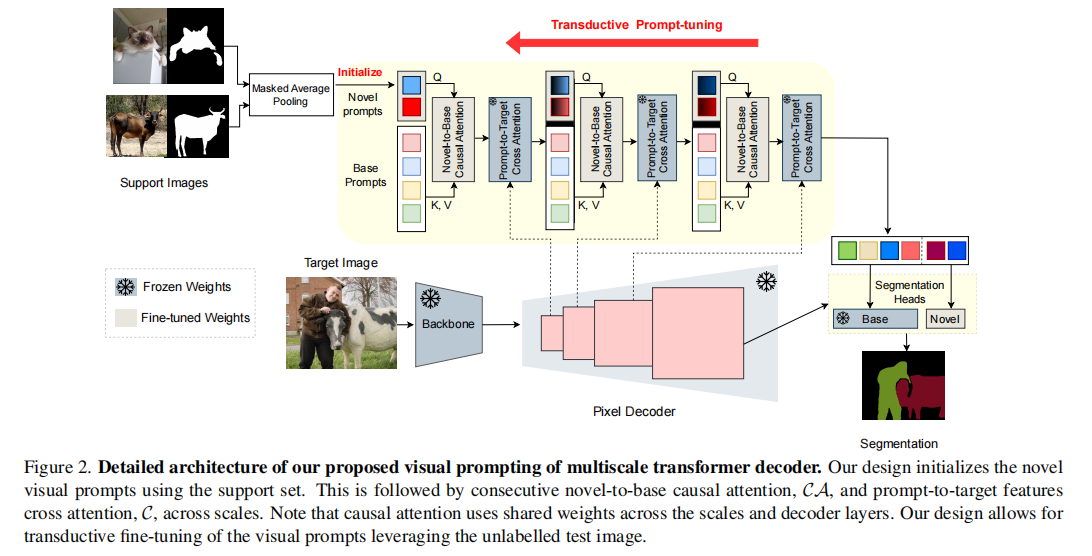
1.视觉提示多尺度Transformer
base视觉提示
假设有$B$个基类,定义$B$个视觉提示分别代表每个基类,并随机初始化它们。这些视觉提示首先通过自我注意学习自身之间的关系,然后用来提示多个尺度的图像特征。在每个解码器层base提示的细化公式如下:
$$
V_B^{(l)} = \mathcal{A}( V_B^{(l-1)} ) + \mathcal{C}(V_B^{(l-1)}, F^{(l-1)})
$$
$\mathcal{A}$代表自注意力,$\mathcal{C}$代表交叉注意力,$V_B^{(l)} \in \mathbb{R}^{B \times C}$是第$l$层的base视觉提示,$F^{(l)} \in \mathbb{R}^{H_l W_l \times C_l}$是第$l$层的扁平(flattened)图像特征。
通过多层transformer注意细化提示后,定义一个分割头,表示为$\mathcal{H}(\cdot)$。这个分割头将最终改进的提示$V_B^{(L)}$和最高分辨率的图像特征$F^{(L)}$作为输入,生成每像素每类的预测。(具体见3)
novel视觉提示
在对基类进行训练之后,冻结模型除了表示基类的视觉提示以外的所有层。假设有$N$个新类,那么添加$N$个novel视觉提示。进一步添加了一个因果单向注意模块,允许novel提示通过base提示增强novel提示。输出被传递给一个分割头,以对新的类进行预测。
novel视觉提示首先通过一个单向的novel-to-base因果注意模块(表示为$\mathcal{CA}$)进行细化,然后将它和base提示连接起来。总的细化公式如下:
$$
V_N^{(l)} = \mathcal{CA}(V_B^{(l)}, V_N^{(l)}) \
V_A^{(l)} = [V_B^{(l)}, V_N^{(l)}] \
V_A^{(l)} = \mathcal{A}( V_A^{(l-1)} ) + \mathcal{C}(V_A^{(l-1)}, F^{(l-1)})
$$
N个novel视觉提示中的每一个都使用掩码平均全局池化进行初始化。
$$
{V}{n}^{\left( 0\right) } = \frac{1}{K}\mathop{\sum }\limits{ {k = 1}}^{K}\frac{\mathop{\sum }\limits_{ {x,y}}{M}{n}^{k}\left( {x,y}\right) {F}{n}^{k}\left( {x,y}\right) }{\mathop{\sum }\limits_{ {x,y}}{M}_{n}^{k}\left( {x,y}\right) },\forall n \in N, (2)
$$
这里,$V_n{(0)} \in \mathbb{R}^{1 \times C}$是新类n的初始novel视觉提示;$F_n^k$表示新类的第k次shot的图像特征;$M_n^k$表示对应的真实二值掩模;$x, y$是空间位置;$N$是新类的总数,$K$是shot的总数。
2.novel-to-base因果注意
直接学习新提示 或 有新提示影响基本提示 可能导致性能下降。
作者假设,novel视觉提示和base提示之间的因果注意可以帮助背景化新类嵌入,减少与base对应物的混淆。基于这种直觉,作者提出了一个novel-to-base因果注意层,它在每个尺度(也即transformer解码器的层)上重复;如图2。
该因果注意模块是一个单层交叉注意,其中解码器第$l$层的键$K^{(l)}$、值$V^{(l)}$和$Q^{(l)}$由如下公式得到:
$$
Q^{(l)} = V_N^{(l)}W^Q; K^{(l)} = V_B^{(l)}W^K; V^{(l)} = V_B^{(l)}W^V
$$
这里,$W^Q$、$W^K$、$W^V$分别为Q、K、V的权重矩阵。参数$W^Q$、$W^K$、$W^V$在该交叉注意模块的所有层上共享,以减少对新类的微调过程中可训练参数的数量,防止过拟合和不良泛化。
该单向novel-to-base因果注意通过如下公式改进每个解码器层$l$处的novel视觉提示$V_N^{(l)}$:
$$
V_N^{(l)} = softmax(Q^{(l)}(K^{(l)})^T)V^{(l)}
$$
于是就产生了一组情境化的novel视觉提示。
3.分割头
base分割头
在该模型的基础训练中,base分割头$\mathcal{H}_B$相对简单,采用三层MLP的形式,将细化的提示有效地投射到类原型中;计算每个像素特征与该原型的(点积)相似度,然后沿着通道/类维度应用softmax来获得每像素每类的概率:
$$
{O}{\text{base }} = {\mathcal{H}}{B}\left( { {V}{B}^{\left( L\right) },{F}^{\left( L\right) }}\right) \
= \operatorname{MLP}\left( {V}{B}^{\left( L\right) }\right) \cdot {\left\lbrack {F}^{\left( L\right) }\right\rbrack }^{\mathrm{T}} , (3)
$$
这里,$O_{base} \in \mathbb{R}^{B \times H \times W}$,类分配可以通过在通道维度使用argmax实现。
novel分割头
理论上可以在小样本推理时使用和公式3一样的方法,但是实践证明这并不有效。主要是由于在这个步骤中存在很少的样本和缺乏基类数据,因此对MLP进行微调会导致明显的过拟合。
因此,作者诉诸于一种更简单形式的novel分割头$\mathcal{H}_N$,只学习在base训练中学习到的MLP的残差(保持固定):
$$
O_{novel} = \mathcal{H}N(V_N^{(L)}, F^{(L)}) \
= [MLP{\textbullet}(V_N^{(L)}) + W_N] \cdot [F^{(L)}]^T
$$
这里,$MLP_{\textbullet}$代表MLP的参数是冻结的,只有权重矩阵$W_N \in \mathbb{R}^{N \times C}$被学习。权重矩阵的初始化方法同novel提示一样(公式2)。
转换提示调优
最近提出的方法表明一个良好的转换设置对小样本密集预测任务的有效性。转换方法对每个未标记的测试图像进行测试时间优化,并利用测试实例的特定特征和信息来改进预测。
为了展示我们的方法的灵活性,在本节中,我们概述了调整我们的模型进行转换推理的过程,通过对视觉提示的转换微调来提高GFSS的性能。我们建立在DIaM [13]中提出的转换损耗的基础上,为了完整性,我们在这里描述它们:
损失被设计用来最大化学习到的特征和对应测试图像的预测之间的交互信息,这是通过最大化$H(O) - H(O|I)$实现的。这里$I$、$O$分别是与像素和预测分布相关的随机变量;$H(O)$为边际熵,$H(O|I)$为条件熵。条件熵$H(O|I)$是由监督支持集的交叉熵损失和对于给定测试图像$I$的预测概率的熵之和给出。边际熵由KL散度损失给出,KL散度损失依赖于之前的估计区域比例。
此外,与DIaM类似,使用知识蒸馏损失来保持基类的性能:
$$
\mathcal{L}{KD} = KL(O{base}^{new} || O_{base}^{old}), (4)
$$
这里,$O_{base}^{old}$是在base训练结束后,在冻结模型上基类的预测概率;$O_{base}^{new}$是使用了我们的附加组件(包括多尺度因果novel-to-base交叉注意和novel提示)来处理新类后,在模型上基类的预测概率。
整体的转换目标函数为:
$$
\mathcal{L}{trans.} = \alpha H(O|I) - H(O) + \gamma \mathcal{L}{KD}, (5)
$$
注意到第一次迭代的转换表现不佳,可能是由于边际分布的初始估计较差。为了解决这个问题,这里只对一组迭代次数应用每像素的交叉熵损失,然后合并等式5中剩余的转换损失,以实现一个更准确的边际分布估计。
实验
数据集:$COCO-20^i$和$PASCAL-5^i$
数据预处理:采用了和DIAM相同的设置。在base训练过程中,同时包含base和novel类的图像被保留,但与novel类对应的像素被重新标记为背景。DIaM中指出,这种方法由于当base模型把novel类预测为背景时存在潜在的模糊性,因此很具挑战性。在微调时,只有novel类被标记进support set,base类标记为背景。为了避免每个novel类的shot 个数不公平,具有多个novel类的图像不放入support set。
评估标准:使用平均IoU(mIoU),GFSS的平均分数是对base和novel的mIoU取平均值。
结果

表1在Inductive和transductive设置上将本文的方法与其他先进方法进行比较,结果表明该模型优于现有的方法。
消融研究:




