Zero-shot Referring Expression Comprehension via Structural Similarity Between Images and Captions
概要
通过图像和标题之间的结构相似性进行零样本参考表达理解
零镜头参考表达理解(zero-shot REC)的目的是根据提供的文本提示在对应的图像中定位边界框,这需要:
- 复杂视觉场景和文本上下文的细粒度的分离
- 理解分离实体之间关系的能力
不幸的是,现有的大型视觉语言对齐(VLA)模型,例如CLIP,在这两个方面都存在困难,因此不能直接用于此任务。为了缓解这一差距,我们利用大型基础模型将图像和文本以(主语、谓语、宾语)的格式分解为三元组。然后,用VLA模型计算视觉和文本三元组之间的结构相似矩阵,并将其传播到实例相似矩阵中。此外,为了使VLA模型具有关系理解的能力,我们设计了一个三重匹配目标,在包含丰富实体关系的管理数据集上对VLA模型进行微调。
介绍
背景、研究现状
视觉定位(visual grounding)是跨计算机视觉和自然语言处理的一项基本任务,其目标是找到图像内容和文本描述之间的对应关系。然而,收集详细的接地注释来训练专业模型是很麻烦的。因此,零样本视觉定位是一个很有吸引力的替代方案。
参考表达理解(REC)作为一种视觉定位任务,其本质是将文本查询与相应的图像区域对齐。因此,在图像和标题中理解关系的能力十分重要。实体不仅是孤立的元素,而是与场景中的其他元素动态交互。在零样本学习的背景下,理解这些关系的任务会更困难,因为模型缺乏能够帮助理解的特定训练实例。
zero-shot REC的最新进展在很大程度上是由大规模视觉语言对齐(VLA)模型的集成驱动的,如CLIP和FLAVA,用它们作为连接文本和图像的桥梁。但是这些方法无法理解实体之间的关系。
本文的解决方法
一种新的零样本视觉定位模型
在本文中,我们专注于REC任务,利用图像和字幕之间的结构相似性,明确地建模它们之间的实体关系,以解决零样本视觉定位问题。具体来说,我们将图像和标题分解为两组三元组,以(主语、谓词、对象)的形式出现,其中每个三元组捕获一对具有它们相互关系的潜在实体。通过综合考虑主语、宾语和谓语的相似性,我们可以找到更好的宾语建议及其引用的匹配。
与现有的工作相比,我们的方法更有原则,并消除了特殊的后处理空间关系解析器。更重要的是,为了提高标题中的关系理解,我们求助于ChatGPT,并利用其强大的上下文学习能力来进行三重分解,以找到给定一个句子的所有可能的关系三元组。与其他方法中的依赖解析器相比,我们的解析在处理长标题时工作得更好,并且不限制空间关系(例如,to the left of),这可以完全捕获动作和交互中的丰富组合语义,如walking、talking to。
改善VLA模型的视觉关系理解
为了解决VLA模型对视觉关系理解的局限性,我们利用了一个具有丰富的关系知识的数据源集合,其中包括人-对象交互数据集和图像场景图数据集。与我们的接地管道类似,我们隔离视觉实体,并在视觉和文本方面构建三元组,然后实现一个三重级的对比学习目标来微调VLA模型。
与现有的基于规则的负提示结构相比,该设计有两个独特的优势:
- 通过将单个图像分解为多个三元组,我们可以获得更多的训练实例,提高训练数据的多样性,而不是简单地使用整个图像进行微调。
- 实体的隔离消除了对图像中其他内容的干扰,为模型微调提供了更加有用的监督信息。我们使用LoRA以参数高效的方式对VLA模型进行微调,提高了其视觉关系的理解,同时保留了从大规模数据中学习到的强大的通用特征表示。
我们将得到的模型称为VR-VLA(视觉关系VLA)。
结果
我们报告了REC数据集上的SOTA零样本视觉定位结果,并在Who的Waldo数据集上显示了有希望的结果,其中我们的零样本方法达到了与完全监督方法相当的精度。
方法
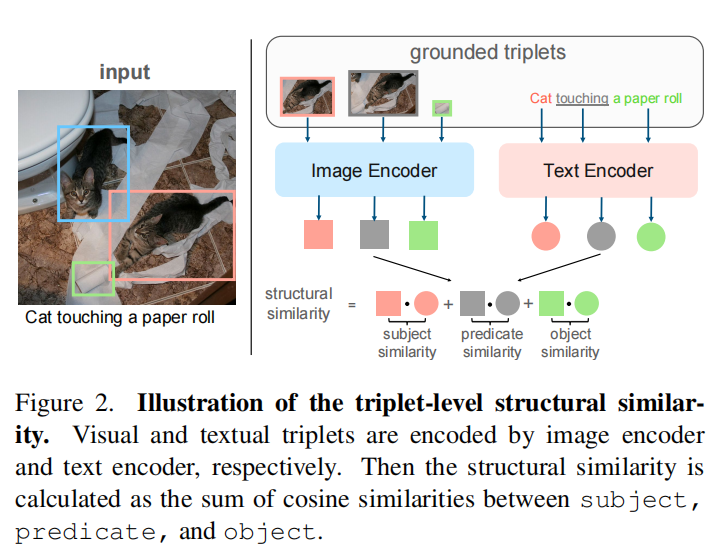
分为两个阶段。首先,解耦图像和文本实体,并以(主题、谓词、对象)的格式构造三元组。其次,计算三重级相似度矩阵,并将其传播到实例级,得到相似度得分最高的边界框。我们的匹配管道的主要重点是精确地建模实体之间的关系,这是通过三级结构相似性来实现的,如图2所示。我们还提供了一个新的配方,使VLA模型具有更好的组合理解能力。
构建三元组
给定字幕$C$、图片$I$。假定字母、图片都由实体集组成,即$\epsilon_{T} = {e_i^T}{i=1}^M$,$\epsilon_I = {e_i^I}{i=1}^N$,M、N分别表示C、I的实体数。分别用$\gamma^T(\cdot)$、$\gamma^I(\cdot)$表示实体对之间的关系
在这一阶段,我们的目标是为两个模态构建实体-关系三元组。
文本三元组表示为$\tau_T = {t_{ij}^T = (e_i^T, \gamma^T(e_i^{T}, e_j^T), e_j^T)|1 \leq i, j, \leq M}$,基数为$M’$。图像三元组表示为$\tau_I = {t_{kl}^I = (e_k^I, \gamma^I(e_k^{I}, e_l^I), e_l^I)|1 \leq k, l, \leq M}$,基数为$N’$。
文本三元组构建
利用LLM强大的上下文学习能力将字幕$C$解析为三联体$\tau_T$。具体来说,我们设计了一个提示来指示ChatGPT解析字幕文本$C$。图3提供了我们如何设计RefCOCO/+/g数据集的提示的概述,进一步的细节阐述如下。注意,提示可能会根据数据集的不同而有所不同,以适应不同的数据分布。如图3所示,提示可分为四个部分:

- 通用指令:为特定的任务定义了一个明确而通用的指令
- 支持细节:包括预期的输出格式、基本元素以及应该或不应该包含的首选项等等
- 上下文学习示例:我们策划了几个上下文学习示例来指导LLM
- 任务指令:附加了输入字母$\tau$
最后,将上述输入输入到LLM中,然后通过LLM完成生成解耦的文本三元组;还会在完成后做一个简单的格式检查。(这个部分叫LLM completion)
视觉三元组构造
在图像中,实体由边界框表示,每个边界框都包含一个单独的对象。这些方框可以由数据集预定义,也可以使用预先训练过的对象检测器进行提取。在不知道这些实体是如何关联的情况下,我们假设每对实体之间可能发生潜在的交互。因此,我们使用笛卡尔积生成视觉对,它包括所有可能的实体组合。注意,当一对实体由同一个实体(方框)组成两次时。这代表了一种自我关系,暗示了实体自己的属性,如颜色(如红色)或自我行为(如walking)。然后我们使用两个实体boxes的并区域$\gamma^T(e_i^{T}, e_j^T)$来表示实体之间的相互关系。
最后,基于类似于ReCLIP的启发式规则过滤掉冗余的三元组$t_{ij}^I \in \tau_I$。具体来说,给定一个文本三联体$t_{ij}^T$,其中它的谓词包含反映一些空间关系的关键字,如to the left of。在这种情况下,我们过滤掉前一个box的中心点(即主体)在后一个box(即对象)的右边这样的视觉框对。这种方法比像ReCLIP中那样构建复杂的空间语义树要简单得多,但它有效地添加了空间上下文并提高了性能。
基于结构相似性的定位
有两种定位思路:
- $text \rightarrow image$:根据文本描述确定图像区域
- $image \rightarrow text$:定位给定图像区域的相关文本描述
鉴于它们的对称性,本节将主要关注$text \rightarrow image$的定位场景。
三元组级别的定位
对于给定的文本三元组$t_{ij}^T = (e_i^T, \gamma^T(e_i^{T}, e_j^T), e_j^T)$,分别将$e_i^T$、$\gamma^T(e_i^{T}, e_j^T)$、$e_j^T$经过VLA文本编码器编码,获得三个文本embeddings$(\mathbf{t}i, \mathbf{t}{i,j}, \mathbf{t}j)$。图像三元组类似,得图像embeddings$(\mathbf{v}k,\mathbf{v}{k,l},\mathbf{v}l)$。这两个三元组的相似度为:
$$
\mathbf{S}(t{ij}^T, t{kl}^I) = cos(\mathbf{t}i, \mathbf{v}k) + cos(\mathbf{t}{i, j}, \mathbf{v}{k, l}) + cos(\mathbf{t}_j, \mathbf{v}_l). (3)
$$
$\mathbf{S} \in \mathbb{R}^{M’ \times N’}$是所有文本、图像三元组的相似度矩阵。之后可以得到一个二进制指标矩阵$\mathbf{B} \in {0,1}^{M’ \times N’}$,计算方式如下:
也就是说,对于每个文本三元组$t_{ij}^T$,二进制指标矩阵B将值1赋给最相似的图像三元组$t_{kl}^I$,将值0赋给所有其他图像。
实例级别的定位
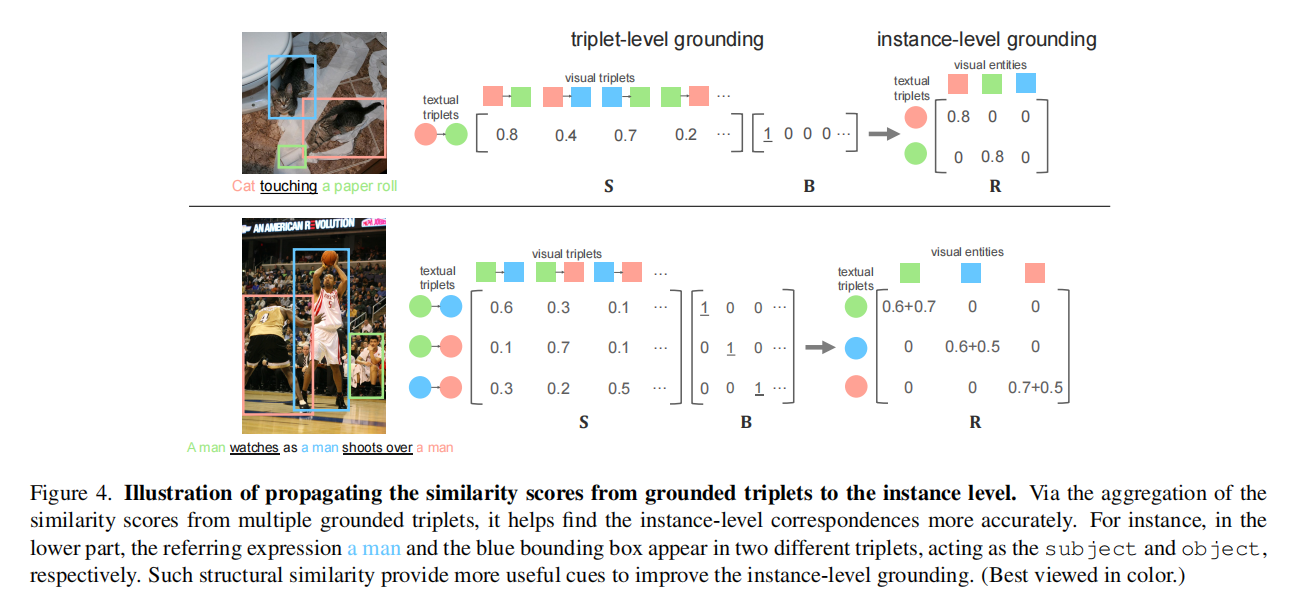
视觉定位问题中的另一个实质性挑战是,三元组中的主语和宾语都可能与其他实体有多重交互。为此,我们设计了一种新的方法来将三元组级别的定位结果传播到实例中。
具体来说,基于三元组级别的定位结果,我们可以计算实例级结构感知相似度矩阵R如下:
$$
\mathbf{R}(e_i^T, e_k^I) = \sum_{j,l} \mathbf{B}(t_{ij}^{T},t_{kl}^{I}) \mathbf{S}(t_{ij}^T, t_{kl}^I) + \sum_{j,l} \mathbf{B}(t_{ji}^{T},t_{lk}^{I}) \mathbf{S}(t_{ji}^T, t_{lk}^I). (4)
$$
等式中的两个项分别考虑了$e_i^T$和$e_k^I$以不同三元组中的主语和宾语出现的情况,如图4下半部所示。通过聚合来自多个定位三元组的相似性得分,它有助于更准确地找到实例级的对应关系。
最后,对于每个文本实体,我们计算最相关的图像实体如下:
$$
\hat{e}_i^I = {argmax}_m \mathbf{R}(e_i^T, e_m^I)
$$
其中$\hat{e}_i^I$表示$e_i^T$对应的视觉实体。如果在等式中实现一个基于阈值的选择来代替argmax函数,我们的方法可以很容易地扩展到一对多的定位场景。但这里将讨论局限于一对一的定位,以获得更清晰的理解。
增强的关系理解
上面算式计算三元组相似度时用的是余弦相似度,试图通过余弦相似度来量化实体之间的关系,并假设VLA模型能够充分把握这些关系。但研究表明这种假设在实践中往往不足。
为了解决这个问题,我们使用了丰富的关系知识的数据集的组合来细化VLA模型。这些数据集包括HICO-det、SWiG和视觉基因组(VG)。值得注意的是,在VG数据集的情况下,我们排除了从COCO中获得的所有图像,以保持零样本协议的完整性,并与我们基于RefCOCO/+/g的实验对齐。
上述提到的数据集提供了目标的注释边界框、文本描述、与其他对象的关系。所以我们可以很容易地遵循我们在三元组级别定位阶段所做的事情来创建视觉-文本的三元组,然后对这些三元组利用对比学习损失。为了表示清晰,我们在等式中使用了相同的符号来计算两个三胞胎之间的相似性。假设$(t_{ij}^{T}$和$t_{kl}^{I}$是两个对应的三元组,我们定义对比损失如下:
$$ \mathcal{L} = \mathop{\sum }\limits_{\left( {t}_{ij}^{T},{t}_{kl}^{I}\right) }\left\lbrack {\log \left( \frac{\mathbf{S}\left( {{t}_{ij}^{T},{t}_{kl}^{I}}\right) }{\mathop{\sum }\limits_{{m,n}}\mathbf{S}\left( {{t}_{ij}^{T},{t}_{mn}^{I}}\right) }\right) }\right.\left. {+\log \left( \frac{\mathbf{S}\left( {{t}_{ij}^{T},{t}_{kl}^{I}}\right) }{\mathop{\sum }\limits_{{m,n}}\mathbf{S}\left( {{t}_{mn}^{T},{t}_{kl}^{I}}\right) }\right) }\right\rbrack $$通过这种改进的方法,可以提高VLA模型对实体间关系的理解和准确评分的能力,从而提高零样本定位能力。(具体优势见概要部分)
实验
建立
RefCOCO/RefCOCO+/RefCOCOg数据来自MS-COCO。RefCOCO包括19,994张图像,其中有142,210个参考表达式。RefCOCO+有19,992张图像和141,564个表达式。RefCOCOg包含26,771张图像,包含104,560个表达式。在RefCOCO和RefCOCO+中,表达式更短,平均有1.6个名词和3.6个单词。在RefCOCOg中,表达式更长,平均有2.8个名词和8.4个单词。
Who‘s Waldo引入了一个以人为中心的视觉定位任务,其中字幕中的所有名称都被屏蔽,迫使模型通过属性和视觉实体之间的交互来链接框和隐藏的[NAME]令牌。字幕很长并且包含了复杂的场景描述。我们使用它的测试分割来进行评估,其中包含6741张图像。每个字幕包含大约30个单词。
评估指标:在RefCOCO/+/g上,我们遵循之前的工作,使用accuracy作为接地结果(grounding results),即如果预测盒与真实区域之间的IoU值大于0.5,则是正确的预测。对于Who‘s Waldo,根据之前的工作,对于给定的文本描述中的人和图像中的边界框之间的对应关系的接地结果,我们报告了在测试集上的真实标签链接的accuracy。
结果
RefCOCO/+/g我们将我们的方法与各种零样本视觉定位模型进行了基准测试,包括彩色提示调优(CPT)、GradCAM 和ReCLIP [54]。ReCLIP代表了零射击REC方法中最新的SOTA。
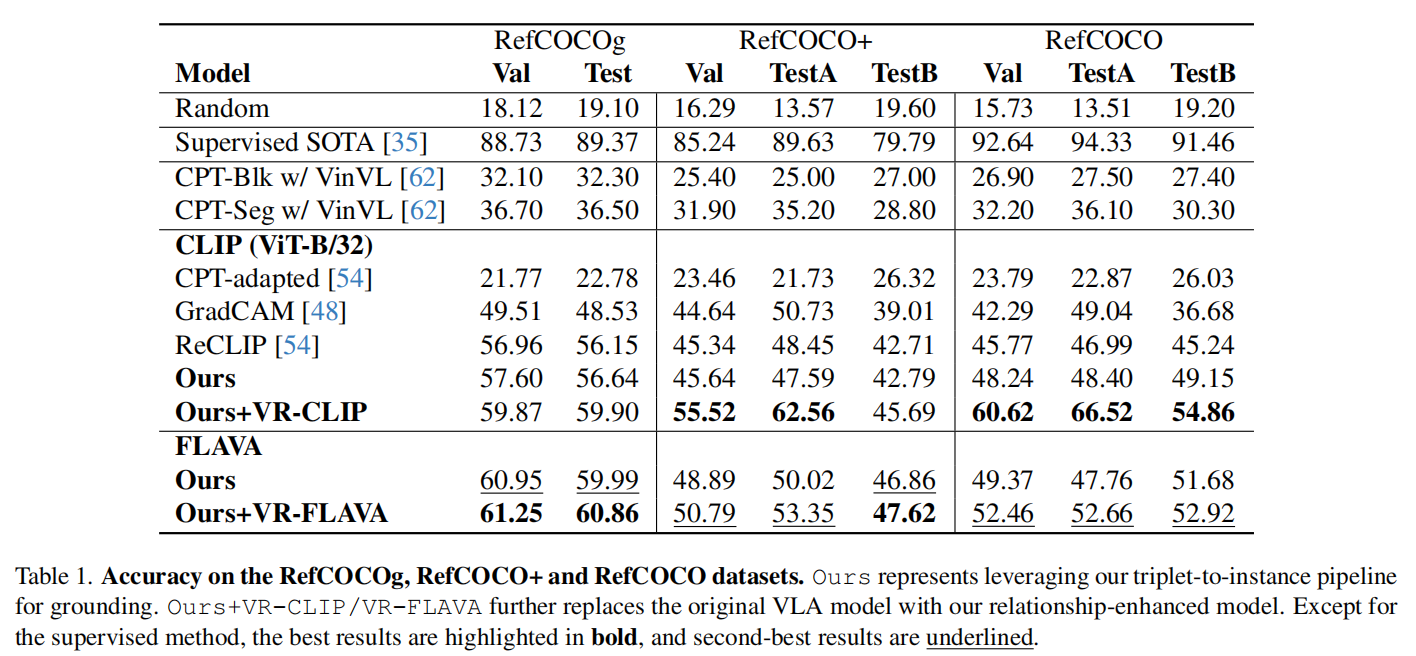
如表1所示,与使用相同CLIP架构的其他模型相比,我们的方法在所有的拆分中都优于其他方法。具体来说,我们的模型比ReCLIP的性能提高了19.53%,平均提高了9.74%。值得注意的是,即使不对主干CLIP模型进行微调,我们的方法也可以超过ReCLIP3.91%,平均为1.05%,这表明基于ChatGPT解析的结构相似性也有助于理解关系。
此外,我们还将我们的方法扩展到另一个VLA模型——FLAVA ,以验证我们的方法的可推广性。毫不奇怪,当集成到我们的匹配管道中时,FLAVA比CLIP模型显示出更优越的性能。这可以归因于FLAVA天生更健壮的架构。在对FLAVA进行微调后,所得到的VR-FLAVA持续地提高了所有数据集分割的性能,加强了我们的方法在增强对各种VLA模型的关系理解方面的有效性。
Who’s Waldo 我们将我们的方法与在接地数据集上训练的模型进行了比较,包括Gupta,SL-CCRF ,MAttNet和UNITER 。Who‘s Waldo方法作为监督基线,如其原论文。此外,我们为我们的数据集适配了ReCLIP,利用它们的语言解析器来识别潜在的参考表达式,然后使用它们的原始方法进行接地。
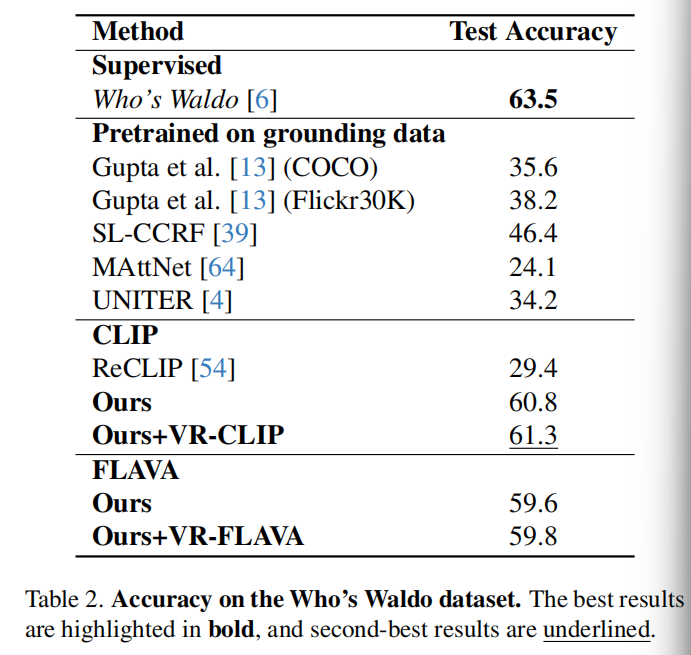
如表2所示,我们的方法优于所有在接地数据集上训练的模型,具有显著的边际。
消融研究
在本节中,我们将对RefCOCOg进行消融研究。这个数据集特别适合于我们的评估,因为它有更长的字幕和丰富的实体交互,使其成为评估每个组件的理想测试平台。
接地管道内组件的有效性
我们探索了两个关键的变化:三元组和VR-CLIP。三重态变量检验了使用三重实例匹配的影响,而不是基本的评分和排序方法,即使用CLIP对每个孤立的盒子进行评分,而不是选择一个相似性最高的盒子。VRCLIP变体评估了微调后的VR-CLIP和原始CLIP模型之间的性能差异。
三元组组件的有效性
分别删除等式(3)中的主语、宾语和谓词术语以探讨其在定位性能方面的有效性
三元组级和实例级定位的有效性
分别删除了等式(4)中的第一项和第二项来验证我们的三元组级定位到实例级定位的设计。


