Few-Shot Object Detection with Foundation Models
小样本目标检测(FSOD)的目的是通过一些训练样本(也叫做support image)来检测没见过的新目标。
视觉特征提取和支持查询的相似度学习是小样本目标检测(FSOD)的两个关键组成部分。现有的工作通常是基于ImageNet预训练的视觉骨干,并设计复杂的度量学习网络用于小样本学习,但其准确性仍然较低。
度量学习也叫做相似度学习。在数学中,一个度量(或距离函数)是一个定义集合中元素之间距离的函数。一个具有度量的集合被称为度量空间。度量学习旨在学习一个度量空间,在该空间中,相同类别的样本距离更近,不同类别的样本距离更远。
本文研究了使用现代基础模型的小样本目标检测。首先,视觉主干采用只有视觉的对比预训练的DINOv2模型,在不调整参数的情况下显示出很强的可转移性能。其次,采用大语言模型进行上下文小样本学习,输入所有类和查询图像proposal。语言指令经过精心设计,以提示LLM在上下文中对每个提案进行分类。语境信息包括proposal-propasal关系、proposal-class关系和class-class关系,它们可以在很大程度上促进小样本学习。本文在多个FSOD基准测试中全面评估了所提出的模型(FM-FSOD),从而实现了最先进的性能。
介绍
视觉主干
首先,预先训练的视觉主干不仅要具有对各种语义概念的辨别能力,而且要具有强大的块级空间定位能力,使其成为下游定位敏感任务的理想选择。
基于这一动机,本文综合评估了多个预先训练好的视觉基础模型,包括MAE、CLIP、SAM和DINOv2,以及不同的检测架构、基于RCNN的框架ViTDet和基于Transformer的框架可变形DETR 。本文的结论是,DINOv2同时经过图像级和块级自监督目标的预训练,并配备了基于Transformer的检测框架,取得了最好的性能。此外,之前的一些工作需要在训练期间更新视觉特征主干,因此在一次前馈传递中只能支持很少的类,本文的模型不需要对视觉主干进行微调。这使得可以使用更大的类集来进行情境化的少镜头学习。
LLM
其次,对object proposals的小样本分类是FSOD的另一个关键组件。本文建议通过在查询图像特征和类原型之间应用交叉注意来生成支持类感知的proposals。但这些proposals仍然有噪声。FSOD的关键挑战是带有噪声的proposals的小样本学习。之前的工作针对这个问题提出了几种方法,从简单的点积到更复杂的深度神经网络,目的是改进有噪声proposal的少镜头分类。
在本文中,本文建议利用预先训练好的LLMs的强大的上下文学习能力来进行FSOD中上下文化的小样本proposal分类。受最近的多模态LLMs的启发,本文仔细设计了语言指令,以提示LLM对每个proposal进行分类,并提供类别和它们的视觉原型之间的映射作为输入指令的一部分。本文的模型可以通过LLM自动利用proposal和类之间的各种上下文信息,包括proposal-propasal关系、proposal-class关系和class-class关系。提取的上下文信息可以在很大程度上促进对同一查询图像的小样本proposal分类。对于模型训练,本文使用元学习对LLM进行了微调。在每个训练过程中,本文为每个类别随机抽取一些视觉样本来计算原型,这在模型训练过程中作为强大的数据增强。
提出的方法
任务定义
在FSDOD中,本文有两个类集合$C = C_{base} \cup C_{novel}, C_{base} \cap C_{novel} = \emptyset$。$C_{novel}$也叫做support classess,其中的样本叫support images。K-shot目标检测就是每个新类都有K个边界框注释作为训练数据。FSOD的目标是在数据丰富的基类训练数据的帮助下,使用少量的视觉示例来检测新的类,并在基类上保持良好的性能。
模型结构
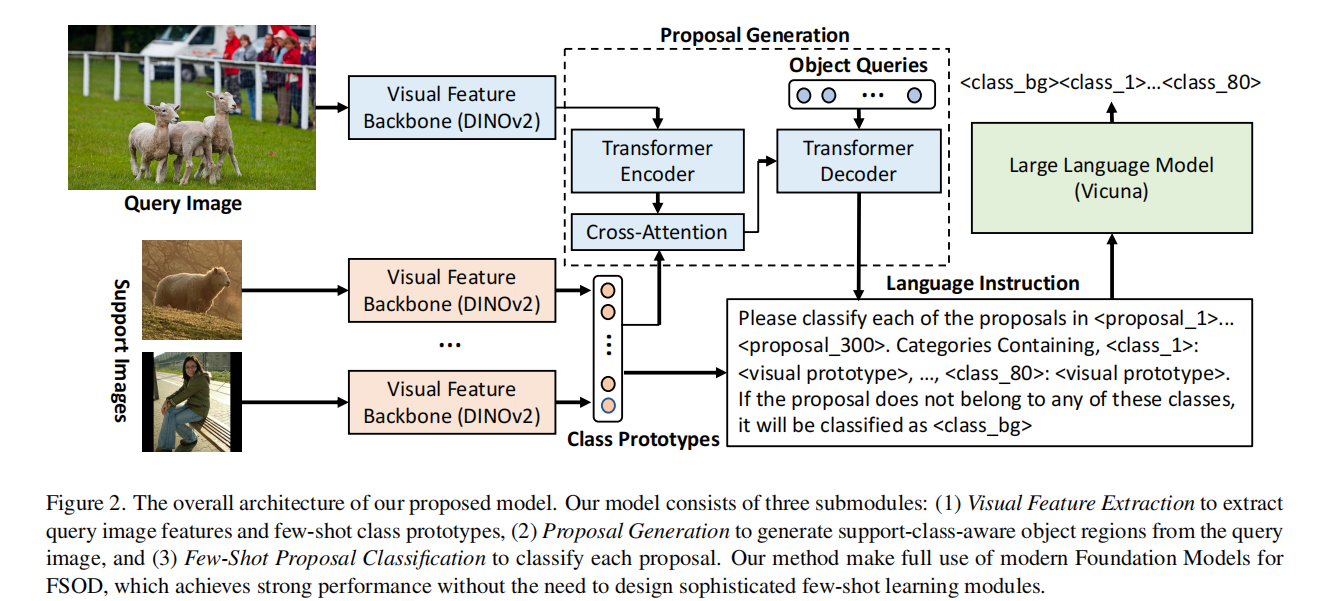
如图2所示,本文的模型主要有以下三个子模块:
Visual Feature Extraction
为query images和support images提取特征表示。
在FSOD中,query image $I_q \in \mathbb{R}^{H_{I_q} * W_{I_q} * 3}$和N-way K-shot support set $S = { { {I_{S}^{j,i}} } {i=1}^{K}}{j=1}^{N}$作为输入,$I_S^{j,i} \in \mathbb{R}^{H_{I_s} * W_{I_s} * 3}$。
用ViT提取query image的特征表示$f_q = \mathcal{F}(I_q)$,并为后面的目标定位保留所有位置块表示。对于support set,同样用ViT提取每张support image的特征表示$f_S^{j,i} = \mathcal{F}(I_S^{j,i})$。实际上,support image会在目标对象附近被裁剪。本文使用RoIAlign根据对象的边界框注释计算对象表示$\overline{f}_S^{j,i} = RoI Align(f_S^{j,i}, box_S^{j,i})$。
那么每个类的原型就是K-shot support特征的平均值${\hat{f}S^j = \frac{\sum{i=1}^{K} \overline{f}S^{j,i}}{K}}{j=1}^{N}$
在本文中,本文使用预先训练过的冻结DINOv2作为本文的特征主干,原因如下:
DINOv2是一种视觉专用的自监督学习模型,在大规模的curated image数据集上进行训练。全局图像级和局部块级自监督目标共同用于训练特征主干。局部块损失可以使模型对局部化敏感,这对下游检测任务很友好。
DINOv2模型在一个大规模的图像数据集上进行了预训练。为了保持DINOv2中的原始知识,本文在训练过程中冻结了特征主干。本文的实验表明,对DINOv2的某些层进行微调并不能提高性能。此外,冻结主干允许本文预先计算每个类的支持特性,这使得在上下文中使用更广泛的类集进行更大的few-shot分类。
使用DINOv2的一个潜在问题是,用于测试的few-shot新类可能在DINOv2预训练中看到。本文认为,预训练只学习图像表示。而如何有效地将基础模型转移到下游任务中仍有待探索,尤其是当训练前的自我监督学习任务和下游检测任务存在较大的差异时这个问题更加突出。
proposal Generation
在使用DINOv2提取视觉特征后,本文使用Transformer编码器-解码器架构来生成proposal。
首先在DINOv2提取的query image的patch tokens上使用多层Transformer编码器。通过Transformer编码器模块,每个块token特征都被全局上下文信息丰富。采用了多尺度变形注意方法,可以加快收敛。
为了生成能感知support class的proposals,本文计算类原型${\hat{f}S^j}{j=1}^{N}$和来自Transformer编码器的query image特征的交叉注意力,以生成能感知support class的query image特征。
然后,能感知support class的query image特征和一系列随机初始化的对象查询$Q = {q_i}{i=1}^{M}$作为Transformer解码器的输入。接着采用几种自注意层和交叉注意层来细化对象查询的表示$\hat{Q} = {\hat{q_i}}{i=1}^{M}$,让它们逐渐收敛到相应的物体上。在Transformer解码器的顶部使用简单的线性层计算每个对象查询的边界框位置$B = {b_i}_{i=1}^M, b_i = [x,y,w,h]$。这样,本文可以为下面的few-shot proposal classification模块生成少量(在本文模型中M=300)支持类感知的对象查询(或者叫proposals)。
few-shot proposal classification
根据映射类别和它们的视觉原型为每个proposal进行分类
在从查询图像中获得proposals以及每个类的原型表示之后,few-shot classification将proposals分类为新类之一或“空”类。本文提出利用LLM强大的上下文学习能力进行上下文化的few-shot proposal classification,通过引入上下文信息提高few-shot分类的准确性,简化设计复杂度量学习网络的工作。
具体步骤:
- 在LLM tokenizer加上class tokens(e.g.:
, …, )和background class token( ) - 为LLM设计以下语言指令*“Please classify each of the proposals in
… . Categories Containing,<class_ 1>: <visual prototype>… : <visual prototype>. If the proposal does not belong to any of these classes, it will be classified as .”*,以对每个proposal执行分类。 - 用相应的proposal特征替换占位符
,然后用一个可训练的投影层,将维数转换为LLM中单词embedding的维数;将<visual prototype>替换为相应的类原型,然后后面跟另一个投影层来将维数转换为LLM中单词embedding的维数。其余的语言指令由LLM tokenizer使用新引入的类标记进行标记化。本文使用Vicuna作为本文的默认语言模型,这是一个仅有解码器的LLM,从Llama进行指令调整得到的。LLM将上述指令的编码后特征作为输入,并通过隐式查找输入指令中定义的类别映射表,为每个proposal生成 token。 - proposal classification的输出标记与输入指令中的proposals保持相同的顺序。通过LLM对生成的标记进行解码后,本文将LLM的分类结果与proposal generation模块中的预测相结合,得到最终的检测结果。
通过提供上述的语言说明,并提示LLM对每个proposal进行分类,本文的方法设计得很简单。更重要的是,本文的模型将所有proposal的输入与所有类的类别映射表一起使用,它可以自动利用proposal和类之间的多重关系,包括proposal-proposal关系、proposal-class关系和class-class关系。提取的上下文信息可以在很大程度上促进对同一查询图像的few-shot proposal分类。
训练框架
分三步:
- 预训练proposal generation模块。在基类上使用可变形的DETR 与冻结的DINOv2主干。遵循DETR中定义的原始损失函数,首先找到预测对象集和真实对象集之间的最优二部匹配,然后将模型优化到这个最优分配。
- 在基类上训练整个模型。proposal generation模块用第一步的训练的结果初始化,LLM用Vicuna模型初始化。为了获得LLM训练proposals的真实标签,本文使用DETR中的二部匹配来为proposals分配标签。然后,本文可以使用next-token预测损失端到端训练LLM,这个损失是在真实proposal标签上计算。在这一步中,proposal generation模块也通过DETR损失进行了微调。
- 根据新类来微调模型。类似第一步和第二步,首先使用下采样的基类和新类对proposal generation模块进行微调。然后,本文使用基类和上采样的新类来微调LLM(因为微调LLM需要更多的训练数据)。
实验结果
数据集
- PASCAL VOC
- MSCOCO
主要结果
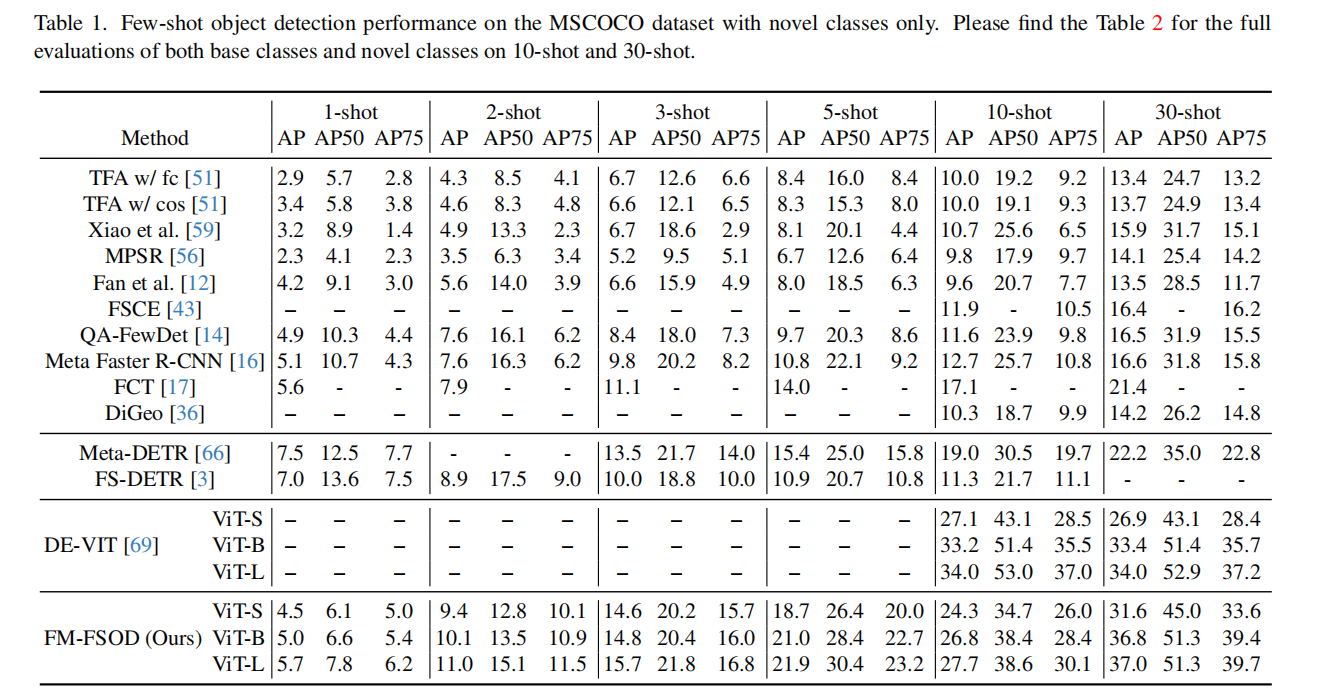
MSCOCO数据集上的:
PASCAL VOC数据集上的
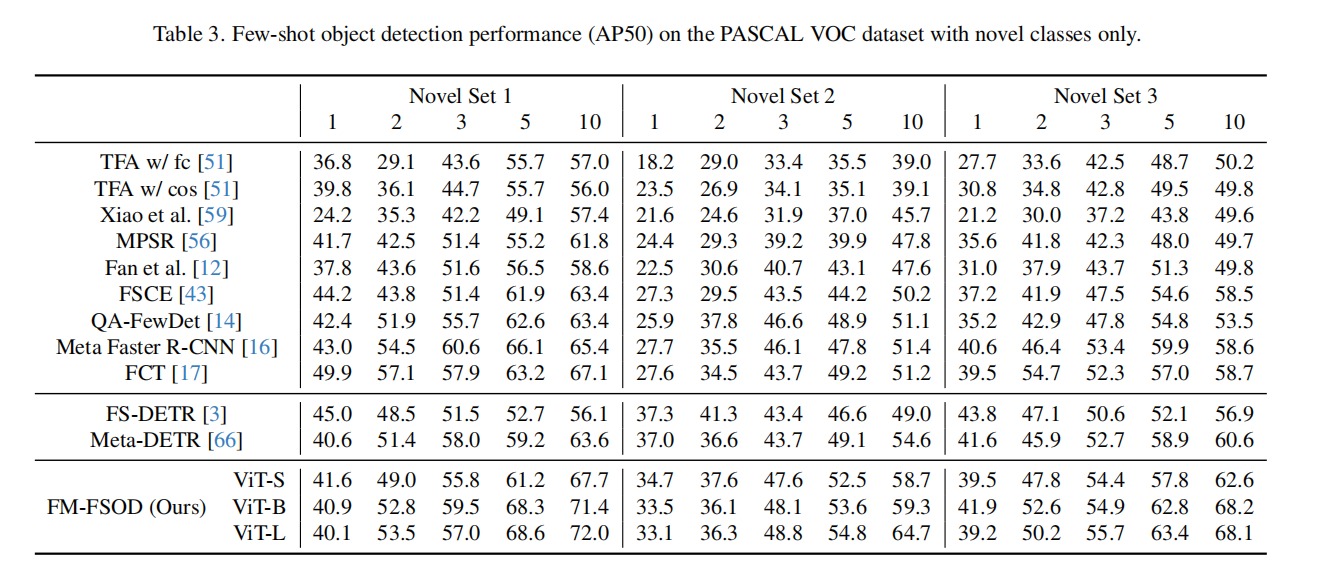
从表1中可以发现,本文的方法明显优于传统的基于Faster R-CNN的FSOD模型,特别是对于shot数量相对较多的设置。这验证了对FSOD使用大型基础模型的有效性。基于DETR的方法通常比基于Faster R-CNN的方法有更好的结果。同样地,本文在更大数量的shot中观察到较大的性能提高,但是也有两种方法(FS-DETR、Meta-DETR)在1次和2次shot上AP50都优于本文的模型。本文认为,这是因为LLM很难用如此少的训练数据进行调整,而且本文不像FS-DETR那样使用外部数据集来进行FSOD训练。未来可能的工作是引入外部数据集用于检测训练,并探索在小数据下使用LLM的有效训练。类似的性能比较见表3。



