ID-like Prompt Learning for Few-Shot Out-of-Distribution Detection
介绍
分布外(Out-of-Distribution, OOD)检测方法通常利用辅助离群值来训练识别分布外样本的模型,特别是从辅助离群值数据集中发现具有挑战性的离群值,以提高OOD 检测能力。但是在有效区分与分布内(In-Distribution, ID)数据很相似的分布外样本时仍面临着限制。这种样本叫做类ID样本(ID-like)。
分布外(Out-of-Distribution, OOD)是指数据样本不属于模型训练时所使用的数据分布的情况。
为此,这篇文章提出了一种新的OOD检测框架,利用CLIP从ID样本的附近空间发现ID-like离群值,从而帮助识别这些最具挑战性的OOD样本。
然后提出了一个提示学习框架,利用识别出的ID-like离群值来进一步发挥CLIP在OOD检测方面的能力。得益于强大的CLIP,我们只需要少量的 ID 样本就能学习模型的提示,而无需暴露其他辅助离群值数据集。
首先构建与 ID 数据高度相关的离群值
具有挑战性的OOD 样本往往与 ID 数据表现出高度相关性,具有高度相似的视觉或语义,这就会导致错误的预测,因此一个自然的想法就产生了:从 ID 样本中提取相关特征来构建具有挑战性的 OOD 样本。
直接从原始图像中构建离群值。对 ID 样本的邻近空间进行了多次采样。在这些样本中,与 ID 提示相似度较低的样本即使它们包含与ID 类别相关的特征,也不会被归为 ID 类别。因此,这些样本自然被选为具有挑战性的 OOD 样本。
并为 OOD 检测引入了新颖的类 ID 提示
我们认为,仅仅依靠 ID 提示不足以解决这一问题。因此,我们引入了额外的提示来加强 OOD 识别
例如,对于dog和wolf,二者很相似,假设开发了一个额外的prompt,称为”dog-like”,与”dog” prompt相似。如果我们能提高 “dog-like” prompt和与 “dog”高度相关的OOD 样本之间的相似度,模型就能通过”dog”提示识别出狗并通过“dog-like”提示识别出具有挑战性的 OOD 样本(如”wolf“)。
具体来说,我们将额外的提示与
1中构建的具有挑战性的OOD 相匹配,创造出与 ID 提示类似的 OOD 提示,从而有效识别具有挑战性的 OOD 样本。
方法
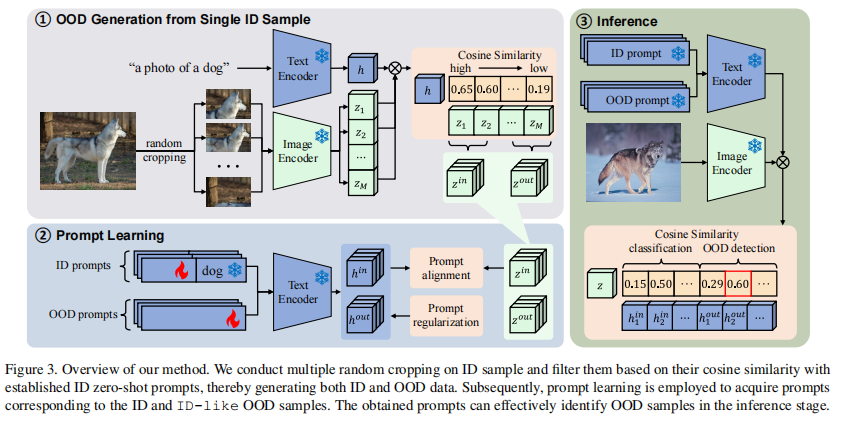
从ID样本中构建离群值
定义训练集$D = {(x_1, y_1), (x_2, y_2), …, (x_N, y_N)}$,N表示样本数。
为了充分探索训练样本的临近空间,我们对每个 ID 样本$x_i$进行多次随机裁剪,得到集合$X_{i}^{crop} = {x_{i,1}^{crop}, x_{i,2}^{crop}, …, x_{i,M}^{crop}}$,M表示裁剪次数。同时,我们使用预先定义的模板(如a photo of a <$y_k$>, $y_k$表示类名)创建相应的类别描述文本$t_k$。
然后利用预先训练好的 CLIP 模型来计算样本集$X_{i}^{crop}$与描述$t_k$之间的余弦相似度。根据余弦相似度的强弱,从高、低相似度段分别提取ID、OOD样本,记做$X_{i}^{in} = {x_{i,1}^{in}, x_{i,2}^{in}, …,x_{i,Q}^{in}}$和$X_{i}^{out} = {x_{i,1}^{out}, x_{i,2}^{out}, …,x_{i,Q}^{out}}$。于是得到$D^{in} = {(x_{1,1}^{in}, y_1), (x_{1,2}^{in}, y_1), …, (x_{N,Q}^{in}, y_N)}$、$D^{out} = {(x_{1,1}^{out}, y_1), (x_{1,2}^{out}, y_1), …, (x_{N,Q}^{out}, y_N)}$
提示学习
为每个类别初始化一个可学习的提示,形成 ID 提示集$T^{in} = {t_1^{in}, t_2^{in}, …, t_K^{in}}$,并初始化一个额外的OOD 提示集合$T^{out} = {t_1^{out}, t_2^{out}, …, t_C^{out}}$。鉴于个别描述所覆盖的范围有限,我们引入了多个OOD描述来增强覆盖范围。与CoOp类似,我们为这些文本描述随机初始化嵌入,然后使用下文中提出的损失函数对它们进行优化。
损失函数
In-distribution loss
为了确保分布内数据的分类性能,我们使用了一个标准的交叉熵损失函数,它度量ID样本的预测标签概率和真实标签之间的差异。在形式上,ID交叉熵损失被定义为:
${\mathcal{L}}_{in} = {\mathbb{E}}_{\left( {x,y}\right) \sim {D}^{in}}\left\lbrack {-\log \frac{{e}^{{s}_{ * }/\tau }}{\mathop{\sum }\limits_{{k = 1}}^{K}{e}^{{s}_{k}^{in}/\tau } + \mathop{\sum }\limits_{{c = 1}}^{C}{e}^{{s}_{c}^{out}/\tau }}}\right\rbrack$其中,${s}{*} = sim ( {\mathcal{T}( {t}{ * }), \mathcal{I}(x) }) $,${s}{k}^{in} = \operatorname{sim}\left( {\mathcal{T}\left( {t}{k}^{in}\right) ,\mathcal{I}\left( x\right) }\right) $,${s}{k}^{out} = \operatorname{sim}\left( {\mathcal{T}\left( {t}{k}^{out}\right) ,\mathcal{I}\left( x\right) }\right)$
Out-of-distribution loss
为了将OOD提示与离群值对齐,我们引入了OOD损失。需要注意的是,在理想的场景中,每个类别都会有一个ID提示和一个OOD提示。然而,为了节省计算资源和提高训练效率,我们将OOD提示的数量固定在100个。因此,当没有足够的OOD提示与ID类别建立一一对应关系时,我们会最大化OOD提示和异常值之间的整体相似性。为了实现这一点,我们建议有以下损失:
$$ {\mathcal{L}}_{\text{out }} = {\mathbb{E}}_{x \sim {D}^{\text{out }}}\left\lbrack {-\log \frac{\mathop{\sum }\limits_{{c = 1}}^{C}{e}^{{s}_{c}^{\text{out }}/\tau }}{\mathop{\sum }\limits_{{k = 1}}^{K}{e}^{{s}_{k}^{in}/\tau } + \mathop{\sum }\limits_{{c = 1}}^{C}{e}^{{s}_{c}^{\text{out }}/\tau }}}\right\rbrack $$此外,我们观察到在训练中使用以下形式的Lout更有利于优化提示:
$$ {\mathcal{L}}_{\text{out }} = {\mathbb{E}}_{x \sim {D}^{\text{out }}}\left\lbrack {\log \frac{\mathop{\sum }\limits_{{k = 1}}^{K}{e}^{{s}_{k}^{in}/\tau }}{\mathop{\sum }\limits_{{k = 1}}^{K}{e}^{{s}_{k}^{in}/\tau } + \mathop{\sum }\limits_{{c = 1}}^{C}{e}^{{s}_{c}^{\text{out }}/\tau }}}\right\rbrack $$Diversity regularization
由于所有的OOD提示都是在同一目标下随机初始化和优化的,在OOD提示之间存在过度相似性的风险。类似的OOD提示可能会导致可检测的OOD类数量的减少。为了减轻这个问题并确保OOD提示的多样性,我们引入了一个额外的损失${\mathcal{L}}_{\text{div }}$,它显式地最大化了提示之间的差异:
$$ {\mathcal{L}}_{\text{div }} = \frac{\mathop{\sum }\limits_{{c = 1}}^{{C - 1}}\mathop{\sum }\limits_{{j = c + 1}}^{C}\operatorname{sim}\left( {{h}_{c}^{\text{out }},{h}_{j}^{\text{out }}}\right) }{C\left( {C - 1}\right) /2} $$这里$h_c^{out} = \mathcal{T}(t_c^{out})$,$h_j^{out} = \mathcal{T}(t_j^{out})$。$t_c^{out}, t_j^{out} \in T^{out}$表示OOD提示中的第c、j个提示
总损失:
$$
\mathcal{L} = \mathcal{L}{in} + \lambda{out}\mathcal{L}{out} + \lambda{div}\mathcal{L}_{div}
$$
推理
在执行分类任务时,我们使用与CLIP相同的分类方法,仅依赖于ID提示进行分类。对于OOD检测,我们将评分函数定义为:
$$ S(x) = \frac{\mathop{\sum }\limits_{{k = 1}}^{K}{e}^{{s}_{k}^{in}/\tau }}{\mathop{\sum }\limits_{{k = 1}}^{K}{e}^{{s}_{k}^{in}/\tau } + \mathop{\sum }\limits_{{c = 1}}^{C}{e}^{{s}_{c}^{\text{out }}/\tau }} $$实验
数据集
与以往的OOD检测任务不同,我们的主要目标是在开放世界环境中实现OOD检测,所以我们不选择一些玩具(如低分辨率)数据集,如CIFAR [16]和MNIST [17]。在我们的工作中,我们遵循MOS [13]和MCM [28]的设置,它们使用ImageNet-1k [3]作为ID数据,以及自然学家[11]的一个子集,将[42]和纹理[2]作为OOD数据。SUN [39]作为一个特定的OOD数据集进行了独立的测试。在MOS [13]之后,这些OOD数据从与ImageNet-1k [3]不重叠的类别中随机选择。此外,一些消融实验使用ImageNet-100进行ID数据。该数据集遵循MCM [28]的配置,该配置从ImageNet-1k中选择100个类作为ID数据。
预训练模型
使用CLIP-B/16作为OOD提示学习的预训练模型。具体地说,,CLIP-B/16,由一个ViT-B/16 Transformer作为图像编码器,一个自注意Transformer作为文本编码器组成。在我们的实验中,我们保持了CLIP的所有网络参数的固定,包括图像编码器和文本编码器,只更新了文本输入端的嵌入层,遵循提示学习的方法。
实施细节
对于少样本训练,需要在完整的训练数据中的每个类中随机选择一定数量的样本来形成训练集。例如,我们从ImageNet-1k中的每个类中随机选择一个(一次)或四个样本(四次)。在构建ID和OOD数据时,我们对每个样本进行M(我们实验中256)次随机裁剪,并根据与手工提示的相似度选择最高的Q(我们实验中32)个和最低的Q个样本。对于ID提示,每个类只有一个可学习的提示,并且保留了类名信息。对于OOD提示,我们将它们的总数设置为C(在我们的实验中为100),并且不保留类名信息。我们将λ1设置为0.3,λ2设置为0.2,并使用AdamW作为优化器。其他超参数设置如下:训练epoch = 3,学习率= 0.005,批量大小=1,token长度L = 16。
评估指标
我们采用以下OOD检测常用的评价指标:(1)分布样本真阳性率为95%时OOD样本的假阳性率(FPR95);(2)受试者工作特征曲线下面积(AUROC);(3) ID分类精度(ID ACC)。
结果
表1是比较结果,表明使用我们的方法可以获得更好的 OOD 检测性能,优于大多数比较结果。更重要的是,即使与那些需要完整数据的方法相比,我们的方法在one shot中仍然有很好的效果。具体地说,在four shot设置中,我们平均获得了 26.08% 的 FPR95 和94.36% 的 AUROC,与相同设置下表现最好的方法相比,分别降低了 12.16% 和提高了 2.76%。
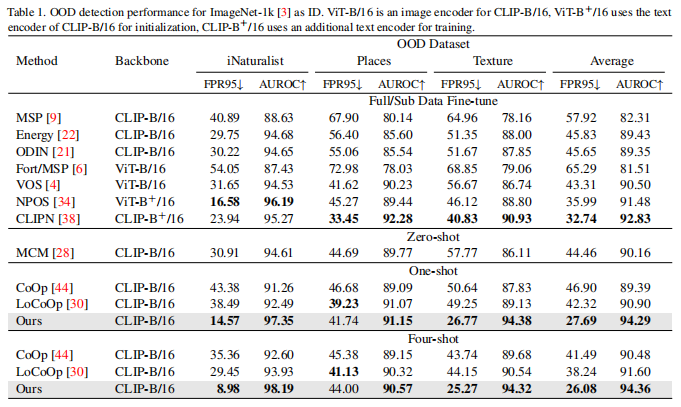
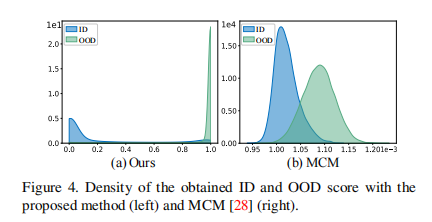
图 4 显示了我们的方法与 MCM 在 iNaturalist 数据集上的比较。我们的方法性能更优,ID 和 OOD 之间的差异明显更大。这表明,在区分 ID 和 OOD 时,MCM 对阈值更敏感,而我们的方法能更直观地区分 ID 和 OOD。
如表2所示,我们的方法优于其他少样本方法,在ID数据上获得了更好的分类结果,为68.28%。

消融研究
离群值的有效性
即时学习的有效性
不同数量的ID-like提示(OOD 提示)的有效性



