背景
大规模的预训练和指令调整已经成功地创建了具有广泛能力的通用语言模型。然而 ,由于额外的视觉输入带来了丰富的输入分布和任务多样性,建立通用视觉语言模型具有挑战性。尽管视觉语言预训练已被广泛研究,但视觉语言指令调整仍未得到充分探索。
为了应对上述挑战,本文提出了一个视觉语言指令调整框架–InstructBLIP,使通用模型能够通过统一的自然语言接口解决各种视觉语言任务。InstructBLIP 使用不同的指令数据集来训练多模态 LLM。具体来说,使用预先训练好的 BLIP-2 模型进行初始化训练,该模型由一个图像编码器、一个 LLM 和一个查询转换器(Q-Former)组成,是二者的桥梁。在指令调整过程中,保持图像编码器和 LLM 不变,对 Q-Former 进行微调。
关键:
- 将 26 个数据集转换为指令调整格式,并将其分为 11 个任务类别。
- 使用 13 个held in数据集进行指令调整,并使用 13 个held out数据集进行零样本评估。
- 提出了 “指令感知视觉特征提取”,具体来说,文本指令不仅提供给冻结的 LLM,也提供给 Q-Former,这样它就能从冻结 的图像编码器中提取指令感知的视觉特征。
held-in evaluation:内部评估,使用同一数据集进行训练和评估,通常采用交叉验证技术将数据集划分为训练集和验证集。模型会在训练集上进行训练,并使用验证集上的数据进行评估和调优。可能导致过度拟合。
held-out evaluation:外部评估,使用独立的、未参与训练的数据集进行评估的。测试泛化能力。
数据集
收集了26个公开的视觉语言数据集,,并将它们转换成指令调整格式,涵盖11个任务分类
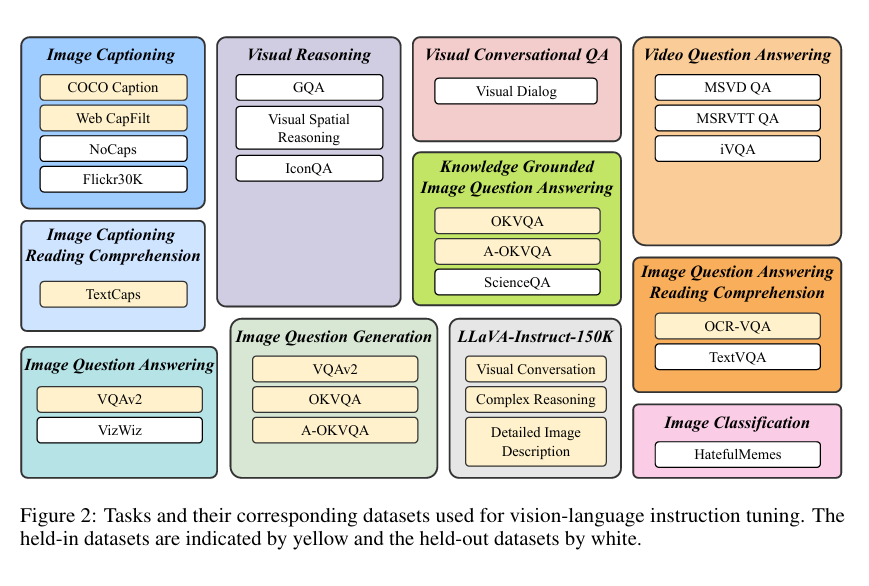
对于每项任务,都用自然语言精心制作 10 到 15 个不同的指令模板。这些模板是构建指令调整数据的基础,其中阐明了任务和目标。对于本质上倾向于简短回答的公共数据集,在一些相应的指令模板中使用了short和briefly等术语,以降低模型过度拟合到总是生成简短输出的风险。
训练与评估
26个数据集分为13个held in(黄),13个held out(白)。
使用held in数据集的训练集进行指令调整,并使用其验证集或测试集进行held in评估。
held out数据集分两种:
- 模型在训练过程中未接触到的数据集,但其任务存在于held in cluster中;
- 在训练过程中完全未见的数据集及其相关任务。
由于held in数据集和held out数据集之间的数据分布会发生变化, 因此处理第一种类型的held out评估并非易事。对于第二种类型,我们完全保留了几项任务,包括 visual reasoning, video question answering, visual conversational QA和image classification
指令感知视觉特征提取
包括 BLIP-2 在内的现有零样本 图像到文本 生成方法在提取视觉特征时采用了与指令无关的方法。这 就导致无论任务是什么,都会有一组静态的视觉表征被输入到 LLM 中。相比之下,指令感知视觉模型可以适应任务指令,生成最有利于手头任务的视觉表征。如果我们预计同一输入图像的任务指令会有很大变化,那么这显然是有利的。
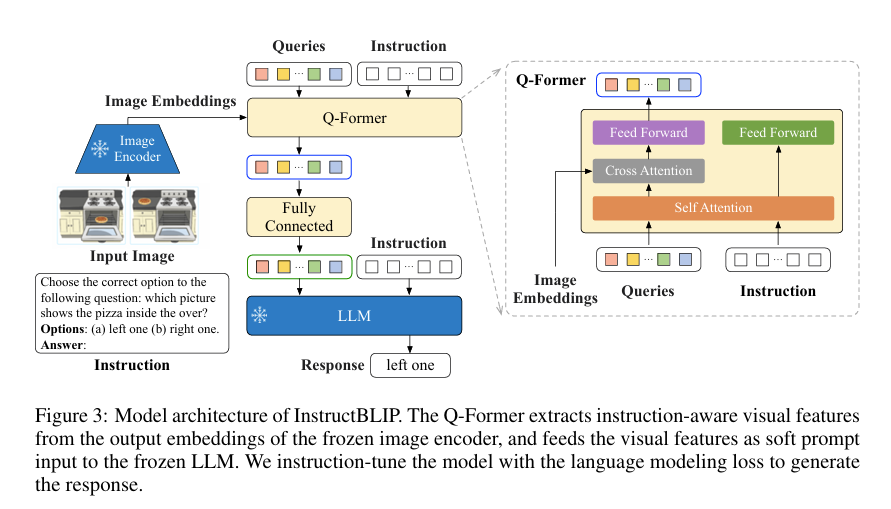
InstructBLIP 利用 Q Former从冻结的图像编码器中提取视觉特征。Q-Former 的输入包含一组 K 个可学习的查询embeddings, 通过交叉注意与图像编码器的输出进行交互。Q-Former 的输出由 K 个编码的视觉向量组成,每个查询embedding一个,然后经过线性投影,送到冻结的 LLM。
与 BLIP-2 一样,Q-Former在指令调整前分两个阶段使用image-caption数据进行预训练(第一阶段使用冻结图像编码器对 Q-Former 进行预训练,以进行视觉语言表征学习 ;第二阶段利用冻结的 LLM 将 Q-Former 的输出调整为文本生成的软视觉提示)在预训练之后,我们通过指令调整对 Q-Former 进行微调,其中 LLM 接收来自 Q-Former 的视觉编码和任务指令作为输入。
在扩展 BLIP-2 的基础上,InstructBLIP 提出了一个指令感知 Q-former模块,该模块将指令文本标记作为额外输入。指令通过 Q-Former的自注意力层与查询embedding进行交互,并鼓励提取与任务相关的图特征。因此,LLM 接收到了有利于指令跟踪的视觉信息。
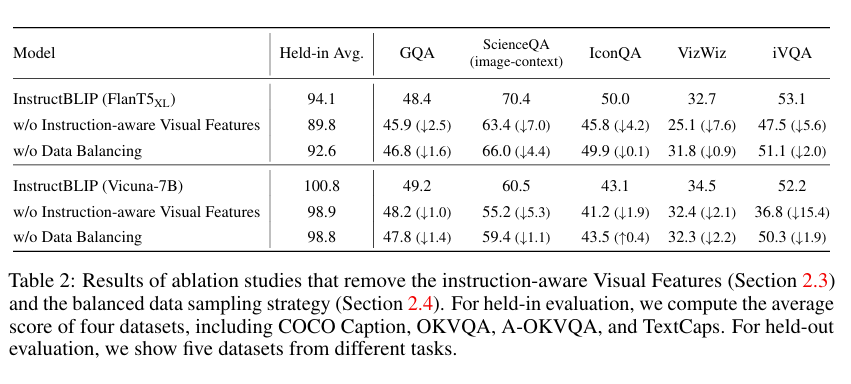
我们通过经验证明(表 2),指令感知的视觉特征提取可以大幅提高 held in和 held out评估的性能
平衡训练数据集
问题:由于训练数据集数量庞大,且每个数据集的大小差异显著,将它们均匀混合可能会导致模型对较小数据集的拟合过度,而对较大数据集的拟合不足。
解决办法:对数据集进行采样,采样概率与数据集大小或训练样本数量的平方根成正比。一般来说,给定 D 个数据集,其大小为 ${S1 , S2 , … ., SD }$,即在训练过程中从数据集 d 中选择数据样本的概率 为 $p_d = \frac{\sqrt{S_d}}{\sum_{i=1}^{D} \sqrt{S_i}}$。在此公式的基础上,我们对某些参数的权重进行了手动调整。 这是因为数据集和任务之间存在固有的差异,尽管数据集和任务的规模相似,但 却需要不同程度的训练强度。
具体来说,降低了以多选题为特色的 A-OKVQA 的权重,增加了需要生成开放式文本的 OKVQA 的权重。表 2 显示,平衡数据集抽样策略提高了保持评估和保持归纳的 整体性能。
推理方法
采用了两种略有不同的生成方法对不同的数据集进行评估。
- 对于大多数数据集, 如 image captioning,open-ended VQA ,直接使用经过指令调整的模型生成回答,然后将其与ground truth进行比较以计算指标。
- 对于 classification 和 multi-choice VQA 任务,沿用了以前的研究成果 (如ALBEF), 采用了词汇排序法:仍然促使模型生成答案,但将其词汇量限制在候选列表中;然后计算每个候选词的对数似然,并选择数值最大的一个作为最终预测结果。这种排序方法适用于 ScienceQA、IconQA、A-OKVQA(多选)、HatefulMemes、Visual Dialog、MSVD 和 MSRVTT 数据集 。
细节
- 结构:得益于 BLIP-2 模块化架构设计所带来的灵活性,我们可以快速调整模型以适应各种 LLM。在 实验中,我们采用了 BLIP-2 的四个变体,它们具有相同的图像编码器(ViT-g/14 ),但冻结的 LLM 不同,包括 FlanT5- XL (3B)、FlanT5-XXL (11B)、Vicuna-7B 和 Vicuna-13B。FlanT5 [7] 是基于 编码器-解码器变换器 T5 [34] 的指令调整模型。另一方面,Vicuna[2] 是最近从 LLaMA[41] 发布的纯 解码器变换器指令调整模型。在视觉语言指令调整过程中,从预先训练好的 BLIP-2 checkpoint初始化模型,只对 Q-Former 的参数进行微调,同时冻结图像编码器和 LLM。由于原始 BLIP-2 模型不包括 Vicuna 的检查点,因此我们使用与 BLIP-2 相同的程序对 Vicuna 进行预训练。
- 训练和超参数。使用 LAVIS 库 进行实施、训练和评估。所有模型都经过最多 60K 步的指令调整,每 3K 步验证一次模型的性能。对于每个模型,我们都会选择一个最佳checkpoint,并在所有数据 集上进行评估。对 3B、7B 和 11/13B 模型分别采用了 192、128 和 64 的批量大小。使用 Adam优化器,$\beta_1 = 0.9,\beta_2 = 0.999$,权重衰减为 0.05。此外,在最初的 1,000 步中对学习率进行线性预热,从 $10^{-8}$增加到 $10^{-5}$,然后进行余弦衰减,最低学习率为 0。所有模型均使用 16 个 Nvidia A100 (40G) GPU 进行训练,并在 1.5 天内完成。
实验
零样本评估
指令调整vs多任务学习
多任务学习与指令调整类似,是一种广泛使用的方法,涉及同时训练多个数据集,目的是提高每个数据集的性能。为了研究在指令调整中观察到的zero-shot泛化的改善是主要来自于指令的格式化 还是仅仅来自于多任务学习,我们在相同的训练设置下对这两种方法进行了比较分析。
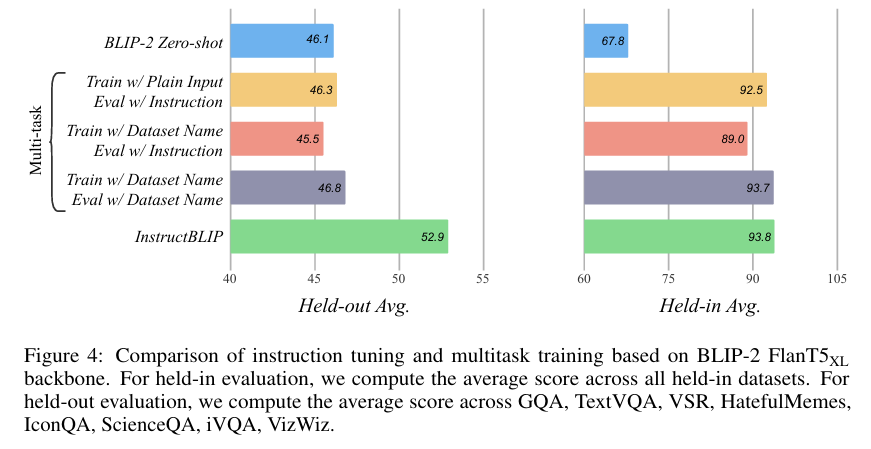
指令调整和多任务学习在保留数据集上表现出相似的性能。这表明,只要模型经过此类数据的训练,就能很好地适应这两种不同的输入模式。另一方面,在不可见的保留数据集上,指令调整比多任务学习有显著提高,而多任务学习的性能仍与原始 BLIP-2 相当。这表明,指令调整是提高模型zero-shot泛化能力的关键。



