CoCa:Contrastive Captioner
探索大规模的预训练base模型在计算机视觉领域有重要意义,因为这些模型可以快速转移到许多下游任务中。
现有的三种基础模型训练方法
1. 单编码模型single-encoder models
只有图像编码器,生成视觉表示。使用人工标注的干净数据集
用途:可以被用到图像和视频理解的下游任务。
局限:这种模型严重依赖图像标注作为标签向量,而不吸收自然语言知识,阻碍了它们在涉及视觉和语言模式的下游任务中的应用。
2. 双编码模型dual-encoder models
可以使用有噪声的网络数据,可以在有噪声的图像-文本对上用对比损失预训练两个编码器。
用途:除了用于视觉任务的视觉嵌入外,由此产生的双编码器模型还可以将文本embedding编码到相同的潜在空间,从而实现新的跨模态对齐功能,如零样本图像分类和图像-文本检索。
局限:这种模型并不直接适用于联合视觉-语言理解任务,如视觉问题回答(VQA),因为缺少联合组件来学习融合的图像和文本表示。
3. 编码-解码模型encoder-decoder models
是生成式预训练模型,可以联合学习视觉和多模态的特征。在预训练期间,该模型在编码器端编码图像,在解码器输出端计算LM(Language Model)损失。
用途:对于下游任务,解码器的输出可以用作多模态理解任务的联合表示。
局限:虽然通过预先训练的编码器-解码器模型获得了优越的视觉语言结果,但它们不产生与图像embedding对齐的纯文本表示,因此在跨模态对齐任务中不可行和效率较低。
CoCa基本特点
CoCa统一了上面三种方法的范式,并训练了一个包含这三种方法的模型能力的图像-文本基础模型。
- 是一个结合了对比损失和字幕损失的图像-文本 编码-解码基础模型,因此具备使用对比方法的模型能力和生成方法的模型能力。
- 两个训练目标共享相同的计算图(computational graph),开销小
- 在人工标注图像和噪声图像文本数据上都进行训练,训练是端到端和从头开始的预训练。通过将所有标签简单地视为文本,无缝地统一了表示学习的自然语言监督。
- 在广泛的下游任务上通过零样本迁移或minimal task adaptation有很好的表现。
具体方法
作者首先回顾了三个不同方式使用自然语言监督的基础模型:单编码器分类预训练、双编码器对比学习和编码器解码器图像字幕。然后引入了CoCa,它们在一个简单的架构下同时具有对比学习和图像到字幕生成的优点。进一步讨论了CoCa模型如何通过zero-shot transfer或minimal task adaptation快速转移到下游任务。
三种用自然语言监督的基础模型
1. Single-Encoder Classification
用交叉熵损失计算:
$$
\mathcal{L}{cls} = -p(y)\log{q{\theta}(x)}
$$
$ p(y)$ 是 GT 标签的 one-hot、multi-hot 或平滑分布, $q_θ(x)$ 是以$ θ $为参数的模型在输入 $x$ 时的预测结果
2. Dual-Encoder Contrastive Learning
$$
\mathcal{L}{Con} = - \frac{1}{N} (\sum{i}^{N} \log{\frac{exp(x_i^{T}y_i/\sigma)}{\sum_{j=1}^{N} exp(x_i^{T}y_j/\sigma)}} + \sum_{i}^{N} \log{\frac{exp(y_i^{T}x_i/\sigma)}{\sum_{j=1}^{N} exp(y_i^{T}x_j/\sigma)}})
$$
$x_i$代表第i个图像-文本对的图像embeddings(归一化的),$y_i$代表第i个图像-文本对的文本embeddings(归一化的)。式子括号里前半部分是计算image-to-text,后半部分是text-to-imge。$N$是batch size
3. Encoder-Decoder Captioning
图像编码器提供潜在的编码特征,文本解码器学习在前向自回归分解( forward autoregressive factorization)下最大化成对文本$y$的条件似然:
$$
\mathcal{L}{Cap} = - \sum{t=1}^{T} \log{P_{\theta}(y_t | y_{<t}, x)}
$$
利用teacher-forcing对编-解码器进行训练,以并行化计算和学习效率最大化。与之前的方法不同,字幕处理器方法产生了一个联合的图像-文本表示,可以用于视觉语言理解,并且也能够通过自然语言生成图像字幕应用程序。
自回归:在训练过程中使用模型自身的预测结果作为输入
teacher-forcing: 在训练过程中使用真实的输出序列作为输入。在Teacher Forcing模式下,模型在每个timesteps t预测输出后,不是将这个预测值用作时间t+1的输入,而是使用真实的数据,即目标序列在时间t+1的真实值。这样,即使前一个预测不准确,网络也可以在准确的数据指导下继续学习12。这种方法可以防止错误的累积和传播,使得训练过程更加稳定
CoCa
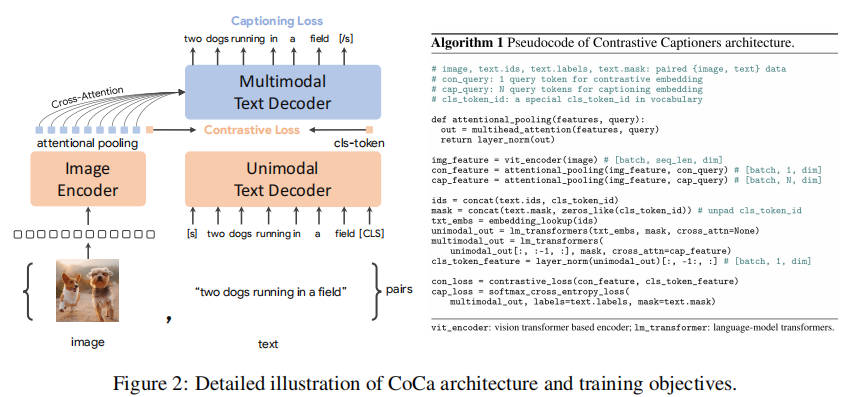
顾名思义,在训练的时候有两个训练目标:基于对比学习的损失函数 Contrastive Loss 和基于生成式图像字幕任务的目标函数 Captioning Loss (一种生成式任务)。
类似于标准的图像-文本编码解码器模型,CoCa通过神经网络编码器将图像编码为潜在表示,例如ViT,并使用causal masking transformer解码器解码文本
causal mask:因果掩码或未来掩码,用于自回归模型中,以防止模型在生成序列时窥视未来的符号。这确保了给定位置的预测仅依赖于该位置之前的符号
$$
\mathcal{L}{CoCa} = \lambda{Con} \mathcal{L}{Con} + \lambda{Cap} \mathcal{L}_{Cap}
$$
Unimodal Text Decoder的结构和 MultiModal Text Decoder 不同,前者没有 Cross-Attention 后者有,因此前者就只是提取纯文本特征,后者学习图像文本的多模态联合表征。
交叉注意力机制:计算流程类似于自注意力机制,但自注意力机制中的查询、键和值都来自同一个输入序列,而交叉注意力机制的查询和键/值来自不同的输入序列。
Image Encoder 的输出 img_feature 先通过一个 Attention Pooler,分别得到 con_feature 和 cap_feature。然后,con_feature 和Unimodal Text Decoder 的输出 [CLS] token 计算对比学习的损失,cap_feature 和MultiModal Text Decoder的输出计算生成任务的损失,完成预训练。
Pooler 是一个简单的多头注意力层,目的是把 Image Encoder 的输出 img_feature 分别转化成 [1, dim] 和 [N, dim] 维的向量。[1, dim]是con_feature(全局),[N, dim]是cap_feature(区域级特征的多模态理解任务)
我们的实验表明,一个单一的池化的图像embedding有助于视觉识别任务作为一个全局表示,而更多的视觉tokens(因此更细粒度)有利于需要区域级特征的多模态理解任务。

- Contrastive Loss 应用于 Image Encoder 和 Text Decoder 的输出端,使得二者都具备独立提取图像特征和文本特征的能力,而且学习到的是偏全局的图文表征。
- Captioning Loss 应用于 MultiModal Decoder 的输出端,使得其具有联合提取图像文本联合表征的能力,而且学习到的是偏细粒度的图文表征。
和ALBEF很相似,但训练目标函数不同;ALBEF 的文本模型部分使用的都是两个 Encoder,不具备直接去做生成式任务的能力,这里用的两个Decoder。
实验
从头开始训练,只有一个阶段
训练数据集: JFT-3B、ALIGN(有噪声的)
主要在三个下游任务进行
- zero-shot transfer,
- frozen-feature evaluation
- finetuning
- 还提出了消融实验
视觉识别任务实验结果:
frozen-feature evaluation和finetuning
CoCa 在 ImageNet 上获得了新的最先进的 91.0% 的Top-1 精度,以及更好的视频动作识别结果。而且,CoCa 模型在视觉编码器中使用的参数比其他方法少得多
跨模态对齐任务实验结果
zero-shot
图像字幕和多模态理解任务
在3个主流 benchmark 上做了实验,分别是 Visual Question Answering (VQA v2), Visual Entailment (SNLI-VE), 和 Visual Reasoning (NLVR2)。在 MSCOCO Captioning 任务上微调了模型



