预训练
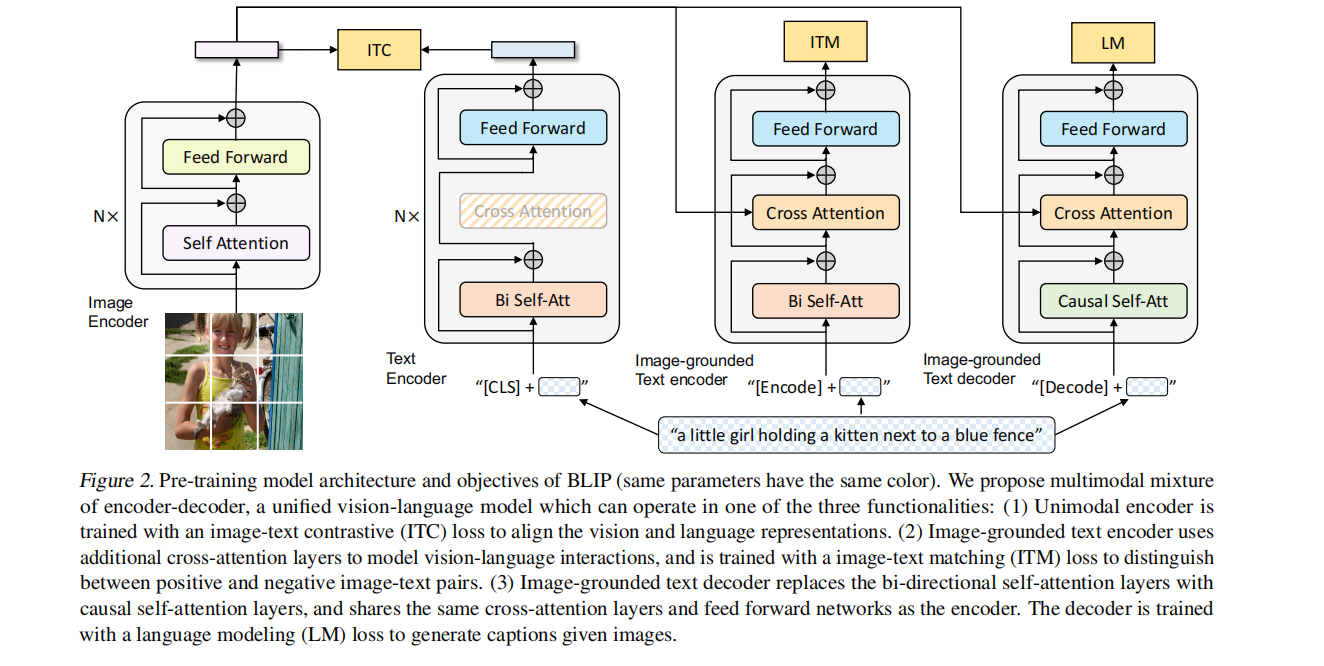
- 图像编码器:ViT的架构。将输入图像分割成一个个的 Patch 并将它们编码为一系列 Image Embedding,并使用额外的 [CLS] token 来表示全局的图像特征。
- 文本编码器:BERT 的架构。[CLS] token 附加到文本输入的开头以总结句子。作用是提取文本特征做对比学习。
- 基于图像的文本编码器:使用 Cross-Attention,作用是根据 ViT 给的图片特征和文本输入做二分类,所以使用的是编码器,且注意力部分是双向的 Self-Attention。添加一个额外的 [Encode] token,作为图像文本的联合特征。
- 基于图像的文本解码器:使用 Cross-Attention,作用是根据 ViT 给的图片特征和文本输入做文本生成的任务,所以使用的是解码器,且注意力部分是 Casual-Attention,目标是预测下一个 token。添加一个额外的 [Decode] token 和结束 token,作为生成结果的起点和终点。
(相同颜色的部分参数共享)
三个训练目标
对比学习损失 (Image-Text Contrastive Loss, ITC)
目标是对齐视觉和文本的特征空间。方法是使得正样本图文对的相似性更大,负样本图文对的相似性更低,在 ALBEF 里面也有使用到。使用了 ALBEF 中的动量编码器,它的目的是产生一些伪标签,辅助模型的训练。
图像-文本匹配损失(Image-Text Matching Loss, ITM)
目标是学习图像文本的联合表征,以捕获视觉和语言之间的细粒度对齐。ITM 是一个二分类任务,使用一个分类头来预测图像文本对是正样本还是负样本。使用了 ALBEF 中的 hard negative mining 技术。
语言模型损失 (Language Modeling Loss, LM)
BLIP 包含解码器,用于生成任务,因此需要一个针对于生成任务的语言模型损失。目标是根据给定的图像以自回归方式来生成关于文本的描述。与 VLP 中广泛使用的 MLM 损失 (完形填空) 相比,LM 使模型能够将视觉信息转换为连贯的字幕。
CapFilt
为了高效率利用噪声网络数据。
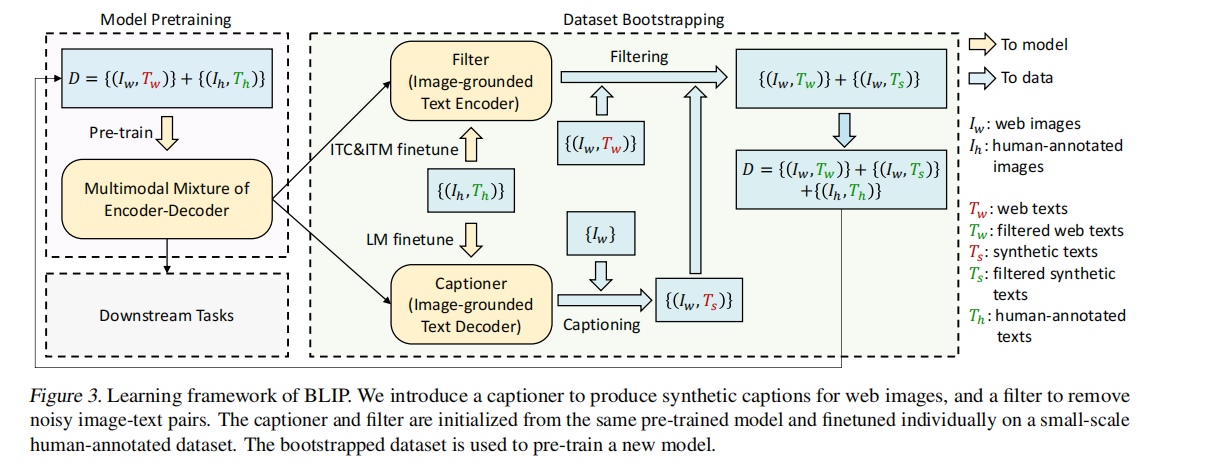
字幕器 Captioner
给一张网络图片,生成字幕。是一个基于视觉的文本解码器,使用 LM Loss微调。给定网络图片 $I_w $,Captioner 生成字幕 $T_s$ 。
过滤器 Filter
过滤掉噪声图文对。是一个基于视觉的文本编码器,看文本是否与图像匹配,使用 ITC 和 ITM 微调。Filter 删除原始 Web 文本 $T_w$ 和合成文本 $T_s$ 中的噪声文本,如果 ITM 头将其预测为与图像不匹配,则认为文本有噪声。
最后,将过滤后的图像-文本对与人工注释对相结合,形成一个新的数据集,用它来预训练一个新的模型。



