一、在school数据库中完成以下练习
sql语句
-- 1 创建表,并定义相应的完整性约束 |
运行结果
由于页面有限,部分查询结果只展示前几条)
2
学生表导入存在问题,因为班长学号不存在,应调整学生顺序,使班长先导入
选课表导入存在问题,具体如下:
0: Duplicate entry '0106-c04' for key '选课.PRIMARY' |
(1)有主码重复的实体,需剔除;(2)表明有学号不在学生表里的
3-7运行结果:
其中3执行失败,因为班长的学号不存在
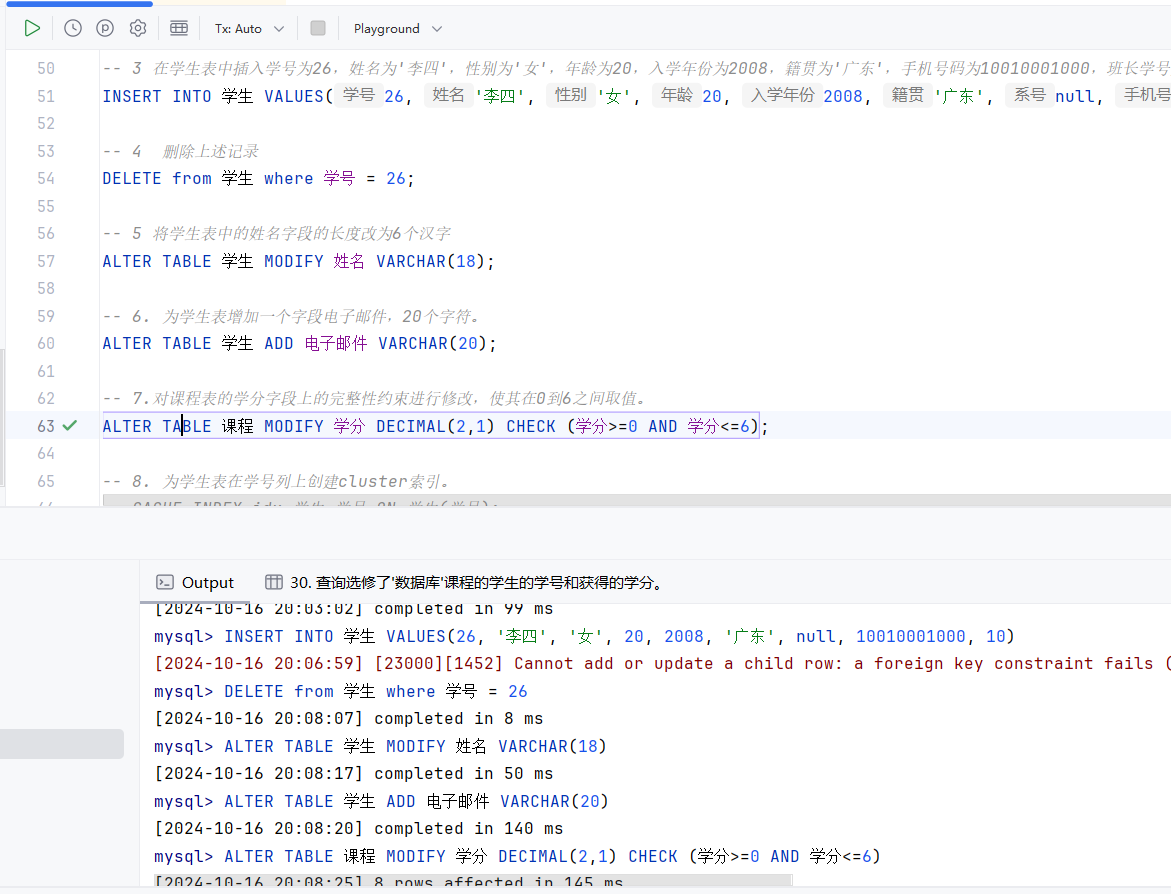
8
MySQL 中无聚集索引概念,通常会在创建表时定义主键自动创建
9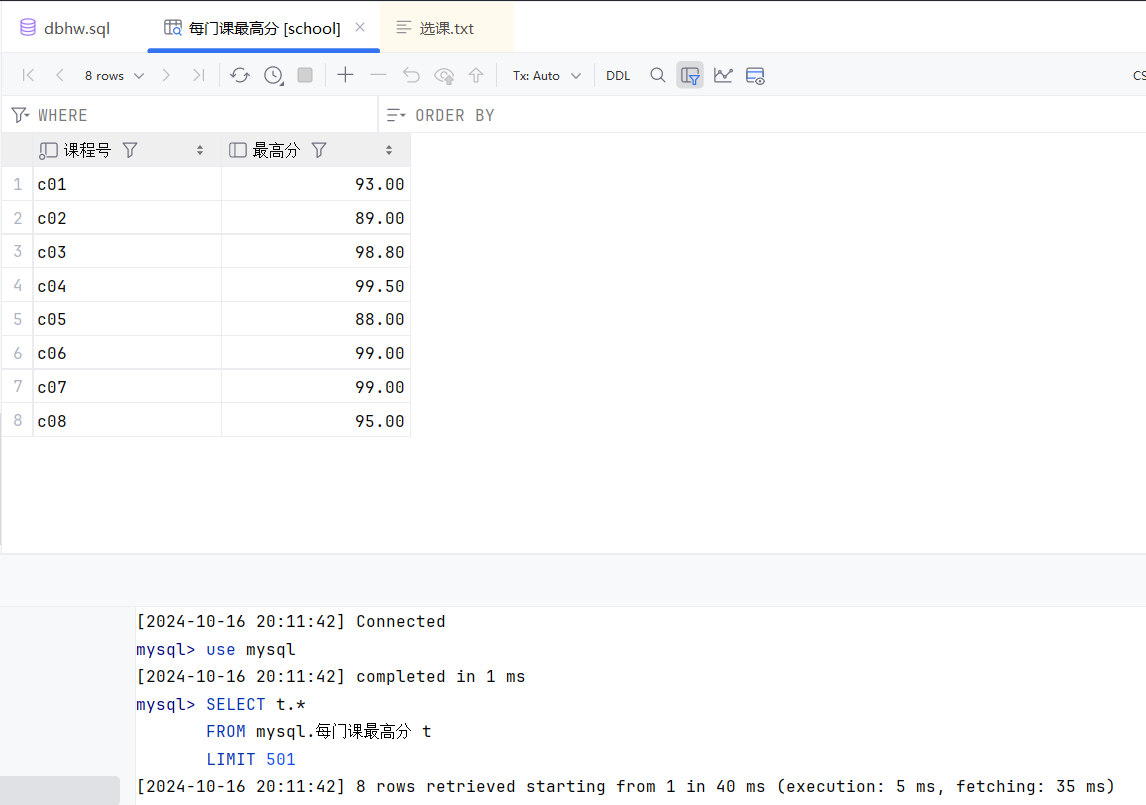
10
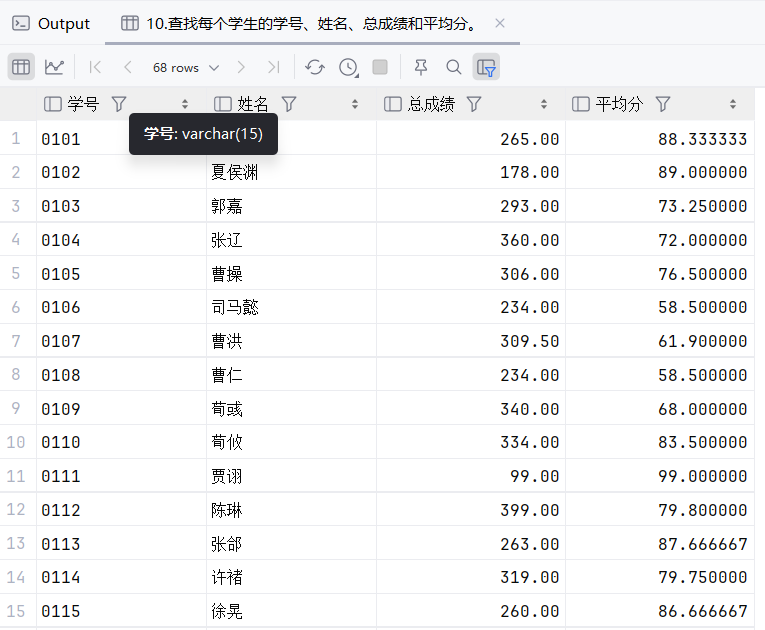
11
学生表中不存在7系的学生,因此执行完后,6系学生的年龄会变为null
12
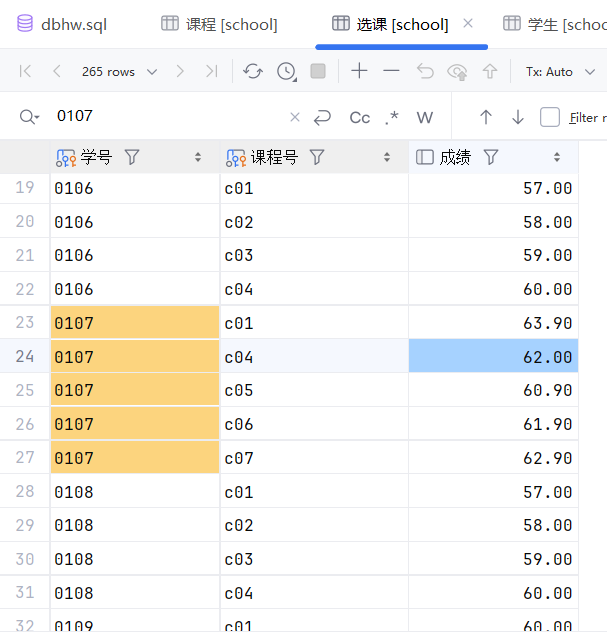
13
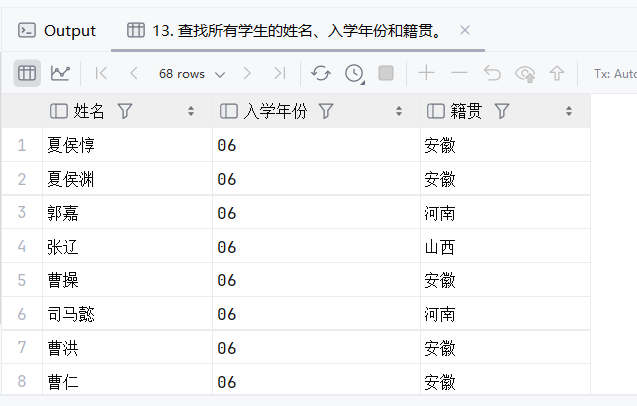
14
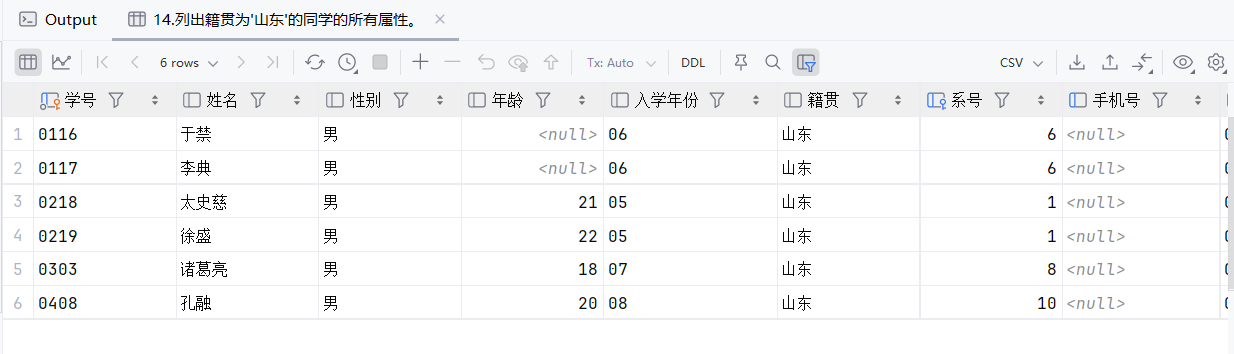
15
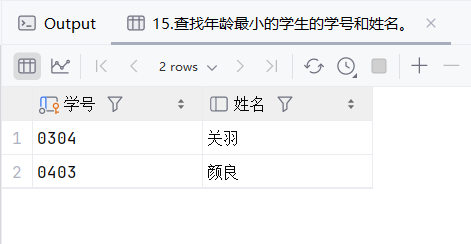
16
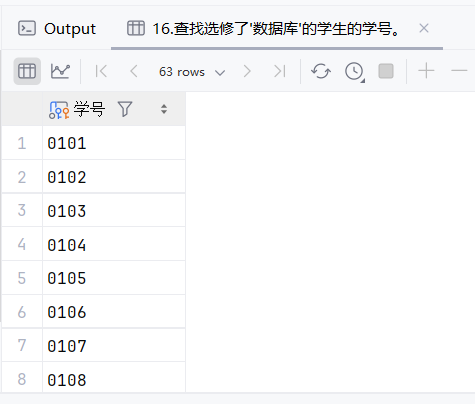
17
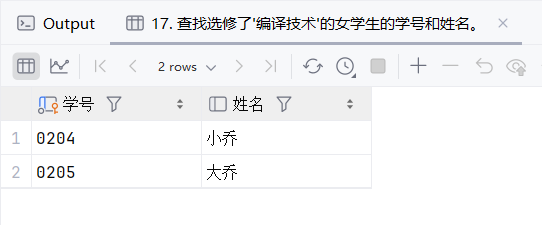
18
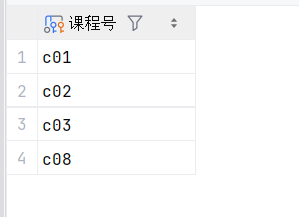
19
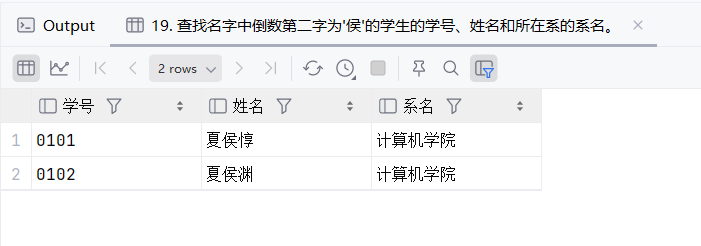
20
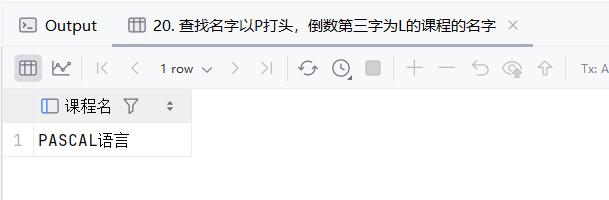
21
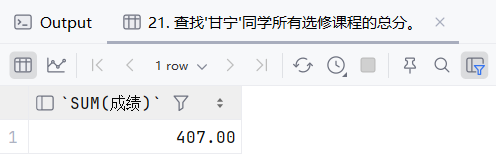
22
23
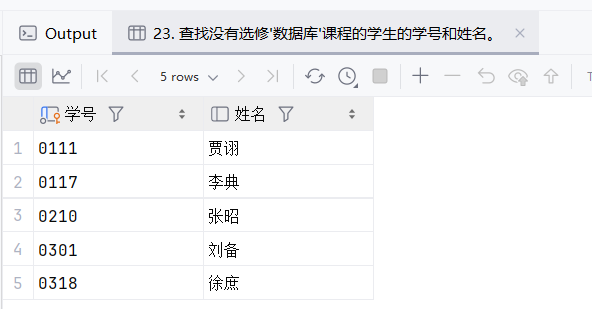
24
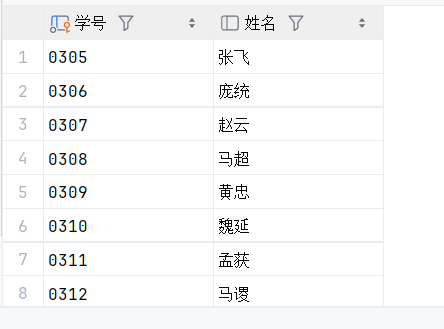
25
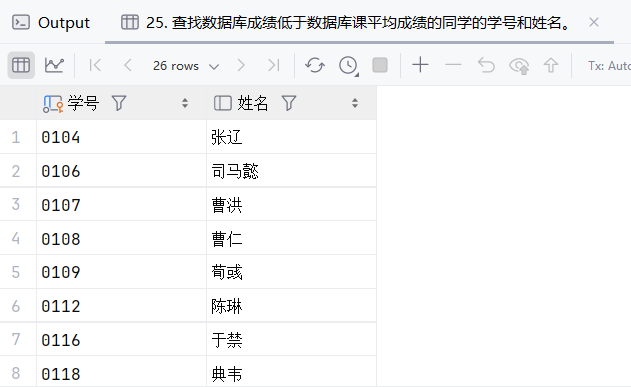
26
27
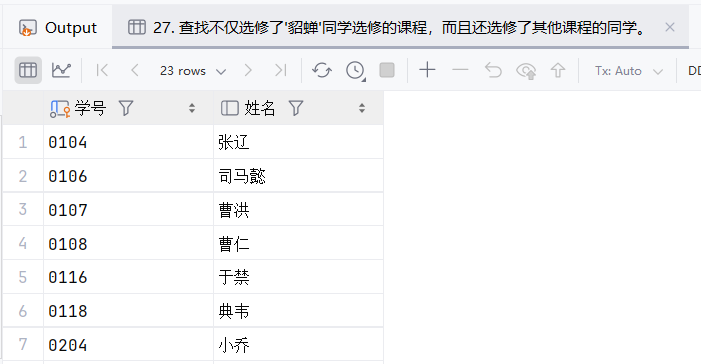
28
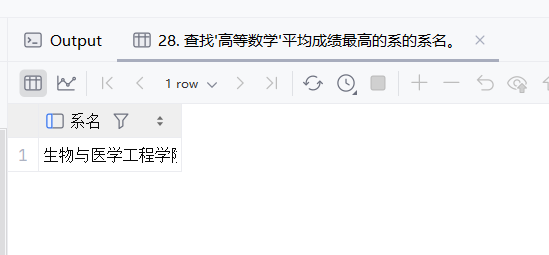
29
无
30
二、回答问题:
SQL语言的特点。
综合统一
高度非过程化
面向集合的操作方式
以同一种语法结构提供两种使用方式
语言简捷,易学易用
创建一个数据库,需要创建几个文件,它们分别是做什么用的?它们对应于三级模式中的哪一级?创建的表存储在什么地方?它们对应于三级模式中的哪一级?
数据库文件类型:
- 主数据文件(Primary Data File):用于存储数据库的所有数据,包括用户数据、系统表、元数据等。每个数据库有且只有一个主数据文件。对应于内模式(物理模式),也就是数据库的物理存储结构。
- 辅助数据文件(Secondary Data File):当主数据文件无法容纳更多数据时,可以创建辅助数据文件来扩展数据库的存储容量。辅助数据文件是可选的,只有在需要扩展时才会创建。同样对应于内模式,用于物理存储扩展。
- 日志文件(Transaction Log File):用于记录数据库的所有事务活动(如插入、更新、删除等),确保在数据库出现故障时能够进行恢复。它主要负责事务管理与故障恢复。日志文件也属于内模式,管理数据库的事务和恢复过程。
表的存储位置:创建的表及其数据存储在主数据文件和辅助数据文件中(即
.mdf或.ibd文件中)。表对应的三级模式:
- 内模式:表在物理存储上的实现方式,例如文件如何存储、数据如何在硬盘上分布、数据如何通过索引来访问。这是数据库系统内部如何管理存储的具体实现。
- 概念模式:从用户角度看,表是逻辑层的数据结构(例如表的字段、主键、外键等)。在这个层次上,用户不需要关心数据的实际存储结构,只关心如何访问和操作表。
可以为表定义哪些完整性约束?它们各自的作用是什么?
- 主键约束(PRIMARY KEY):确保每一行都有唯一标识的字段,主键列的值不能重复,且不能为空。
- 唯一约束(UNIQUE):保证列或列的组合在表中具有唯一值,可以为空值,但多个空值允许存在。
- 外键约束(FOREIGN KEY):用于维护数据之间的参照完整性,确保一个表中的值必须在另一个表的主键或唯一列中存在。
- 非空约束(NOT NULL):防止列中出现空值,确保必须为该列插入有效数据。
- 检查约束(CHECK):用于限制列中的数据值范围或条件,确保数据符合指定的条件。
自然连接和等值连接有什么差别?
- 自然连接自动基于两个表中相同的属性列进行连接,省去了连接条件
- 等值连接是基于两个表中某一列(或多列)值相等的连接,通常需要使用ON或WHERE条件来指定连接的条件
子查询分为哪几种?它们之间有什么区别?
子查询按照与外部查询的联系不同,分为普通子查询和相关子查询
普通子查询:与外部查询无关,可单独执行得一组值。
相关子查询:把外查询的列值作为检索条件的条件值
索引有什么作用和缺点?
作用:
- 加速查询:通过创建索引可以显著加快数据的查询速度。
- 提高排序性能:索引有助于快速实现排序操作。
- 加速表连接:索引有助于在连接表时提高性能。
缺点:
- 占用空间:索引会占用额外的存储空间,特别是大数据集上的多索引。
- 增加修改成本:对带有索引的表进行插入、删除或更新时,索引需要同步更新,增加了写操作的开销。
基本表和视图有什么区别?视图有什么优点?什么样的视图是可以更新的?
区别:
- 基本表:物理存在的表,存储实际数据。
- 视图:逻辑上的虚拟表,不存储数据,仅是对查询结果的命名。
视图的优点:
- 能够简化用户操作
- 使用户能够以多种角度看待同一数据
- 提供了一定程度的逻辑独立性
- 能够对数据提供安全保护
可更新的视图:通常视图涉及单个表,并且视图中包含了基础表的主键和非计算列,才能进行更新。
请针对第三章SQL语言讲义中的除法例子,给出其他两种除法的实现方法。
假设需要查询选修了全部课程的学生姓名- 方法一:使用group by...having
SELECT Sname FROM Student WHERE Sno IN (
SELECT Sno FROM SC GROUP BY Sno HAVING COUNT(SC.Cno)=(SELECT COUNT(Cno) FROM Course
);
- 方法二:使用双not exists
Select Sname From Student
Where Not Exists
(Select * from Course
Where Not Exists
(Select * from SC
Where Sno=Student.Sno
And Cno=Course.Cno));
- 方法三:参考第二章除运算的定义,将其翻译为sql语句
SELECT Sname FROM Student WHERE Sno NOT IN (
SELECT Sno FROM (
- 存在课程没选的学生
SELECT Sno, Cno FROM Student CROSS JOIN (SELECT Cno FROM Course) AS T1 - 所有学生都选择了所有课程的选课表
EXCEPT SELECT Sno, Cno FROM SC AS T2 - 做差运算,得出有课没选的情况
) AS T3
);



