概念
知识蒸馏
把一个大的模型(教师模型)里面的知识萃取蒸馏出来,并浓缩到一个小的(学生)模型中。是一种用于模型压缩和迁移学习的技术,其主要思想是通过将一个大型模型的知识传递给一个小型模型来提高小型模型的性能。
软标签和硬标签
| 硬标签 | 软标签 | |
|---|---|---|
| 定义 | 一种离散的、确定性的类别表示方式。每个样本被赋予一个明确的、唯一的类别标签 | 一种连续的、概率分布形式的类别表示方式。每个样本的标签是一个概率向量,表示它属于每个类别的概率。 |
| 应用 | 常用于传统的监督学习任务,如分类问题 | 常用于知识蒸馏等场景,其中大型模型的输出可以作为软标签传递给小型模型。 |
| 软标签包含了样本与多个类别之间的相似度信息,因此它们可以使模型更加平滑地处理类别之间的边界,并减少对单一类别的过度依赖 |
蒸馏温度
知识蒸馏中的一个超参数,它控制了模型预测的软标签分布的“软化”程度。蒸馏温度的作用是在生成软标签时引入一个温度参数,从而调整标签的相对概率分布。这个温度参数通常是一个正的实数。例如分类问题最后总是用softmax函数将输出转化为概率分布,用上蒸馏温度就变成如下形式:
$$
softmax(z/T)_i = \frac{e^{z_i/T}}{\sum_j e^{z_j/T}}
$$
作用:
软标签的平滑性: 增加蒸馏温度会使软标签的概率分布更平滑。较高的温度将导致更平缓的概率曲线,使得模型更容易学到相对均匀的分布。这对于小型模型的训练过程中更容易捕捉大型模型的知识,因为软标签的平滑性有助于抑制训练时的过拟合。
控制标签的尖峰性: 较低的温度会使软标签的分布更接近硬标签,即更尖锐,更接近确定性。这可能使得模型更注重大型模型中预测概率最高的类别,但相对容易受到噪声的影响。
控制模型的自信程度: 蒸馏温度还可以影响模型的自信度。较高的温度导致模型更不确定,而较低的温度则会使模型更自信。这可以在训练过程中控制模型的泛化行为。
控制损失函数的平坦性: 由于知识蒸馏的损失函数通常涉及到交叉熵,温度参数也可以影响损失函数的平坦性。这有助于更稳定地训练小型模型,特别是当大型模型和小型模型结构不同或训练数据较小的情况下。
流程
Object-Aware Knowledge Extraction:adaptively transforms object proposals and adopts object-aware mask attention to obtain precise and complete knowledge of objects.
Distillation Pyramid:introduces global and block distillation for more comprehensive knowledge transfer to compensate for the missing relation information in object distillation
- knowledge extraction
- knowledge transfer
obj token和cls token的区别是什么呢?论文的意思好像是obj关注的是图像的提议框里的对象,cls关注的是整个这张图像,一个是部分,一个是整体,但是obj的生成不也要用“这个图像包含哪个类别的目标”的信息,岂不是和cls一样了?
mmdection
- apis 为模型推理提供高级 API。
- structures 提供 bbox、mask 和 DetDataSample 等数据结构。
- datasets 支持用于目标检测、实例分割和全景分割的各种数据集。
- transforms 包含各种数据增强变换。
- samplers 定义了不同的数据加载器采样策略。
- models 是检测器最重要的部分,包含检测器的不同组件。
- detectors 定义所有检测模型类。
- data_preprocessors 用于预处理模型的输入数据。
- backbones 包含各种骨干网络。
- necks 包含各种模型颈部组件。
- dense_heads 包含执行密集预测的各种检测头。
- roi_heads 包含从 RoI 预测的各种检测头。
- seg_heads 包含各种分割头。
- losses 包含各种损失函数。
- task_modules 为检测任务提供模块,例如 assigners、samplers、box coders 和 prior generators。
- layers 提供了一些基本的神经网络层。
- engine 是运行时组件的一部分。
- runner 为 MMEngine 的执行器提供扩展。
- schedulers 提供用于调整优化超参数的调度程序。
- optimizers 提供优化器和优化器封装。
- hooks 提供执行器的各种钩子。
- evaluation 为评估模型性能提供不同的指标。
- visualization 用于可视化检测结果。
faster RCNN核心代码
mmdet/models/backbones/resnet.py
mmdet/models/necks/fpn.py
mmdet/models/dense_heads/rpn_head.py
mmdet/models/roi_heads/standard_roi_head.py
疑问
teacher甚至student是指代什么?
知识蒸馏里的术语
embedding和全连接有什么区别?感觉两者都是把高维向量平铺开。
embedding层主要用于处理离散型数据,而全连接层则可以处理任意类型的数据
nn.BatchNorm2d和nn.LayerNorm有什么区别和联系?
计算
$$
nn.BatchNorm2d : \text{E}[x]c = \frac{1}{N \times H \times W} \sum_{n=1}^N \sum_{h=1}^{H} \sum_{w=1}^{W} x_{n,c,h,w} \nn.LayerNorm : \text{E}[x]{c} = \frac{1}{H \times W}\sum_{h=1}^{H} \sum_{w=1}^{W} x_{c,h,w}
$$应用场景
- BatchNorm通常用于CNN(卷积神经网络)的卷积层之后,用于调整数据的分布,加速网络训练。由于BatchNorm依赖于mini-batch的统计数据,因此它对于较小的batch size可能不太稳定。
- LayerNorm则常用于RNN(循环神经网络)和Transformer等模型,因为它们在处理序列数据时,每个样本的长度可能不同,而LayerNorm可以对每个样本进行独立的归一化操作。
nn.MultiheadAttention和F.multi_head_attention_forward有什么区别?
相比
nn.MultiheadAttention,F.multi_head_attention_forward提供了更底层的控制,允许用户直接操作多头注意力的各个组成部分。然而,由于它不是一个模块,因此它通常不会被直接嵌入到神经网络模型中。相反,它可能被nn.MultiheadAttention或其他高级模块所使用。
ABCMeta是什么?
ABCMeta是一个元类(metaclass),用于定义抽象基类的元信息。通过将ABCMeta作为元类,可以在类定义阶段对类进行检查和修饰。ABCMeta元类提供了一些功能,例如检查子类是否实现了抽象方法、注册具体实现类等。
在Python中,类是通过类来创建的,而创建类的类就是元类。元类的主要目的是控制类的创建行为。Python的特别之处在于可以创建自定义元类,而ABCMeta就是这样一个自定义元类,用于创建自定义的抽象基类。
logits是什么?
logits(或称为分数、原始分数、未校准的输出等)是模型输出的原始、未归一化的预测值
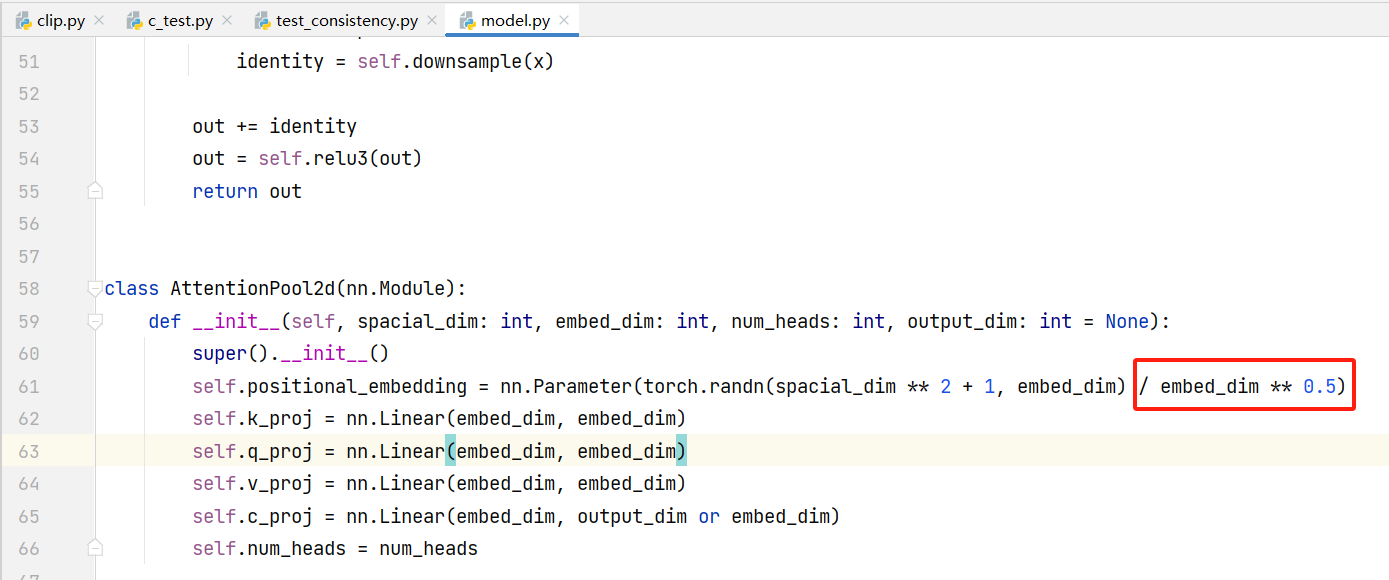
这里为什么要除以embedding向量的开方?一种初始化规则?
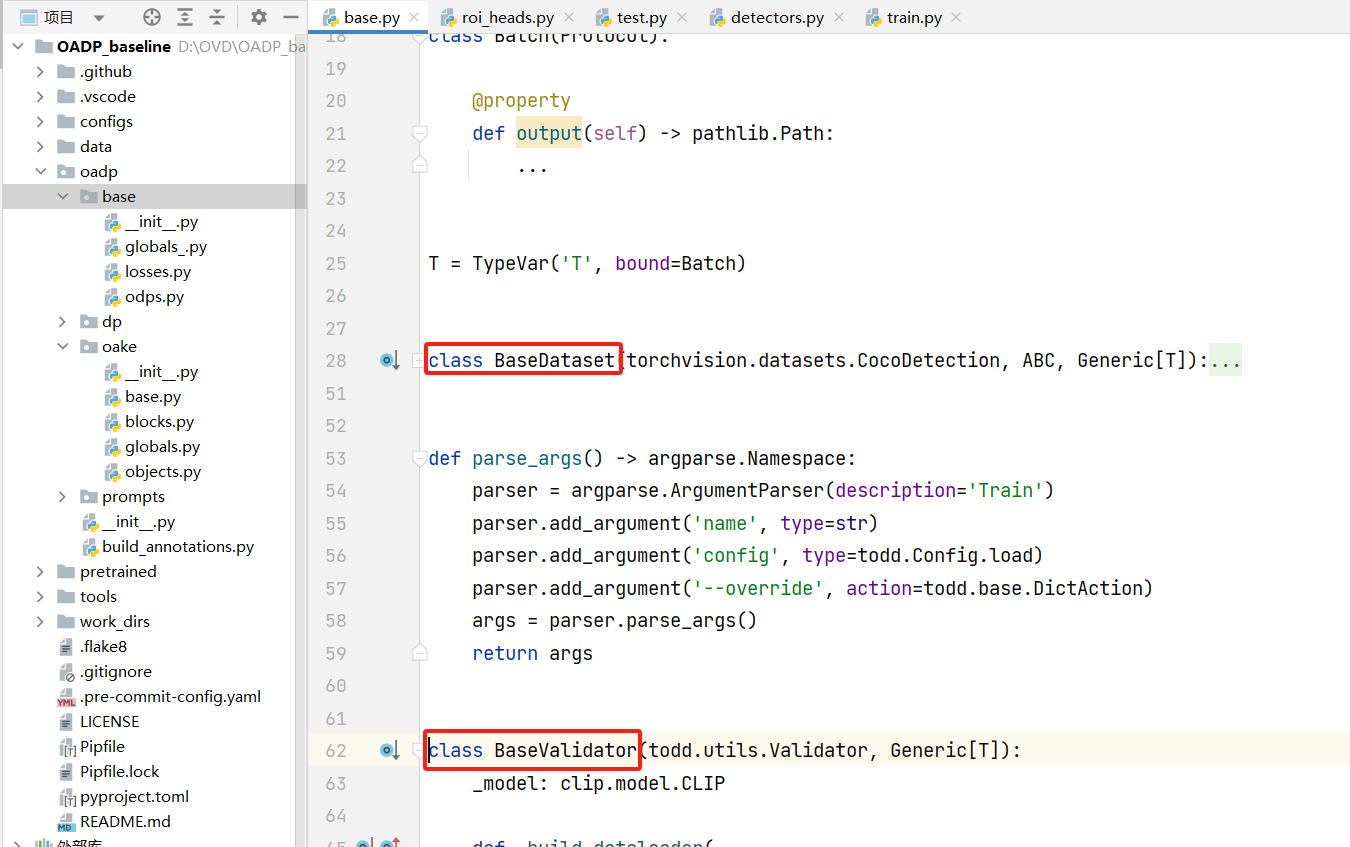
oake模块下base.py文件中Validator类有什么作用呢?
OKAE这三文件都可以单独运行,独立的把需要的特征提取出来保存。因为OADP中global、block和object使用的蒸馏特征在提取的时候会特别耗时,所以作者把这三个蒸馏特征的提取过程单独用这三个文件预先生成之后保存起来了,后面DP部分训练时候是直接读取的这些特征
oadp/oake/objects.py里Dataset类的_expand方法有什么用?为什么要扩大bbox,而且还分了很多种扩大模式?
为了把proposal的不规则区域转化成正方形,因为CLIP的输入是224*224的正方形,可以认为这样expand之后有助于减小输入CLIP特征的形变
Compose和nn.Sequential有什么区别和联系?
- 联系:
- 二者都提供了一种顺序执行的方式,可以将多个操作或层按照特定的顺序组合在一起。
- 它们都简化了模型的构建过程,使得代码更加清晰和易于管理。
- 区别:
- 功能和应用领域:Compose主要用于组合图像预处理操作,是torchvision.transforms模块中的一个类。而nn.Sequential则用于构建神经网络模型,是PyTorch中torch.nn模块的一个容器类。
- 组成部分:Compose中的操作通常是对图像的变换,如裁剪、旋转、标准化等。而nn.Sequential中的层通常是神经网络的各种组成部分,如线性层、卷积层、激活函数等。
- 使用方式:Compose通常与图像数据集一起使用,用于在将数据输入到神经网络之前进行预处理。而nn.Sequential则直接定义了一个神经网络模型,可以通过前向传播函数将数据传递给模型并获得输出。
oadp/dp/classifiers.py的BaseClassifier类中的bg_embedding是什么?
mixin是什么意思?
Mixin实质上是一个带有部分或全部实现的接口或类,它可以被其他类继承或混入,从而将这些功能组合到子类中。Mixin模式的主要作用是代码复用,通过减少代码冗余度,使代码更加清晰、可维护和易于扩展。
参考
zip 是 Python 的一个内置函数,用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象
for foreground, bbox in zip(foregrounds, bboxes): |



