整体架构
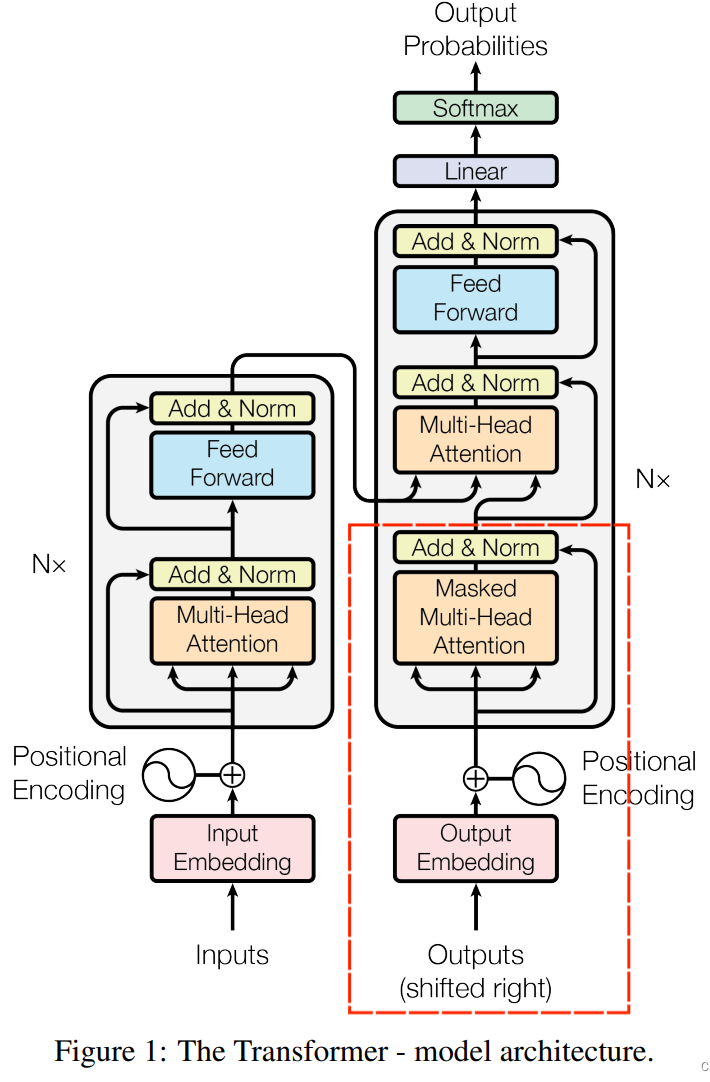
图上全部为训练过程,去掉虚线框里的就是推理过程(没有正确答案输入的部分了)
Word Embedding词嵌入
将输入(输入句子有m个词)转化为向量,假设嵌入维度为n,则一个词对应一个n维向量,整个向量维度为m x n。
Positional Encoding位置编码
$$
PE(pos, 2i) = sin(\frac{pos}{10000^{2i/d_{model}}}) \
PE(pos, 2i+1) = cos(\frac{pos}{10000^{2i/d_{model}}})
$$
将每个位置信息编码后与对应位置词的编码相加,这样后面的自注意力机制可以同时考虑输入的词本身和顺序信息。
Encoder(多次反复使用,一般为6次)
多头注意力机制
Add&Norm
- 残差结构:将输入矩阵X与上一步得到的矩阵相加,这里是经过多头注意力机制得到的矩阵Z,待会Feed Forward后得到的矩阵还会有一个Add&Norm步骤
- LayerNorm:对一个样本的所有特征计算均值和方差,然后归一化
Feed Forward
就是普通的全连接网络
$$
FFN(x) = max(0, xW_1 + b_1)W_2 + b_2
$$
Decoder(多次反复使用,一般为6次)
与Encoder差不多,但是新增加了一个Masked Multi-Head Attention。
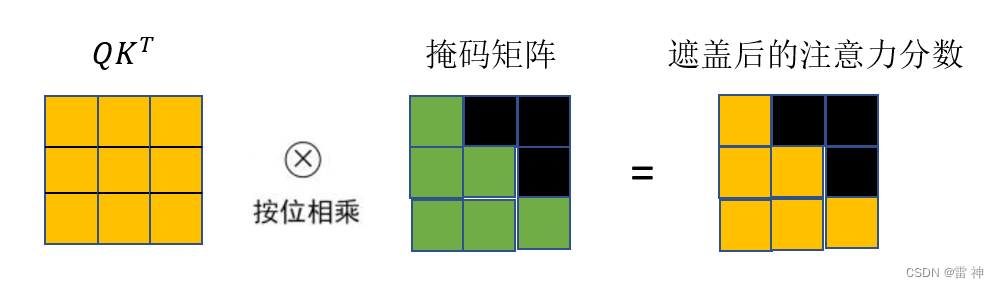
Masked Multi-Head Attention(带掩码的多头注意力机制)
Transformer训练过程采用了Teacher Forcing的训练模型,会将原始输入和正确答案都会喂给模型
为了防止模型知道后续输出单词(正确答案)的信息,需要掩码机制掩盖后面词的信息。
实现方式:构造掩码矩阵(下三角矩阵),将归一化后的注意力分数与掩码矩阵按位相乘。其他部分和多头注意力机制一样。