CLIP:Constrastive Language-Image Pre-training
概念
embedding:一种将高维数据(如文本或图像)转换为较低维度的向量表示的技术
结构
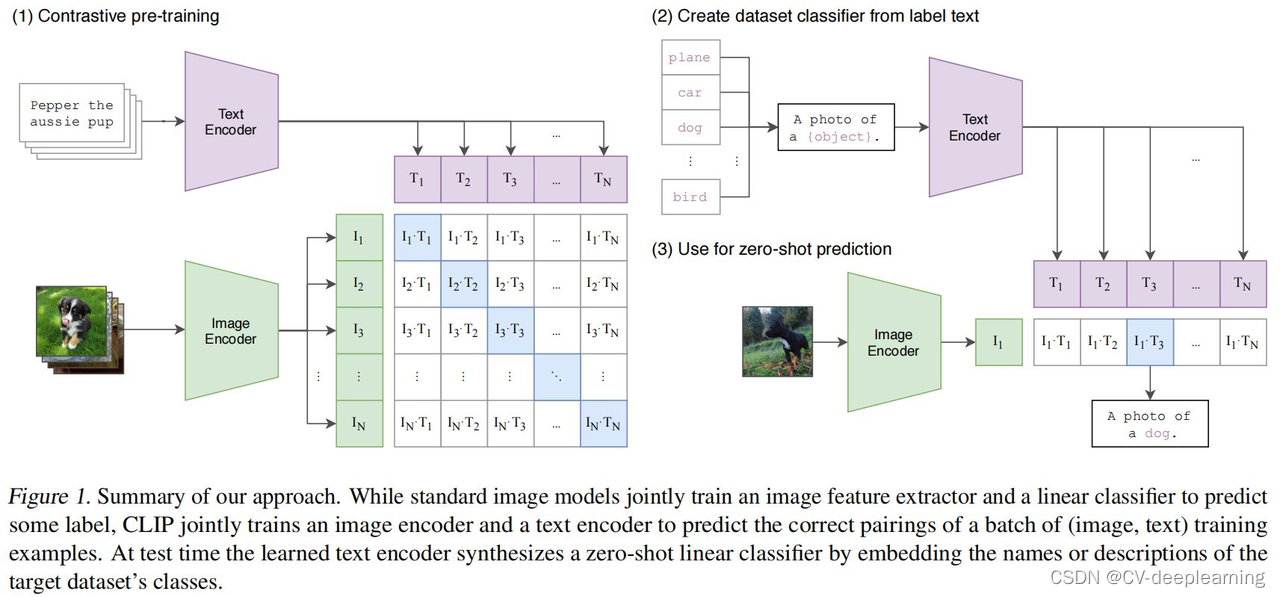
推理过程
把需要分类的图片送入image encoder得到特征,拿图片的特征和所有文本特征算余弦相似性,选最相似的那个文本特征对应的句子,从而完成了分类任务
余弦相似度cosine similarity
用来度量文本与图像之间的对应关系,值越大表示对应关系越强。其实就是计算两个向量夹角的余弦值。
训练过程
图片和文字配对,分别输入到Image Encoder、Text Encoder得到特征。若每个training batch有n个图像-文本对,就可以得到n个图片-文本对。
配对的图片-文本对就是正样本,描述的是同一个东西。特征矩阵里对角线上的都是正样本,矩阵中非对角线上的元素都是负样本。有了正负样本,模型就可以通过对比学习的方式去训练,不需要任何手工标注。
Image Encoder:ViT
结构如图,概括一下就是一个Patch+Position Embedding加多个Transformer Encoder
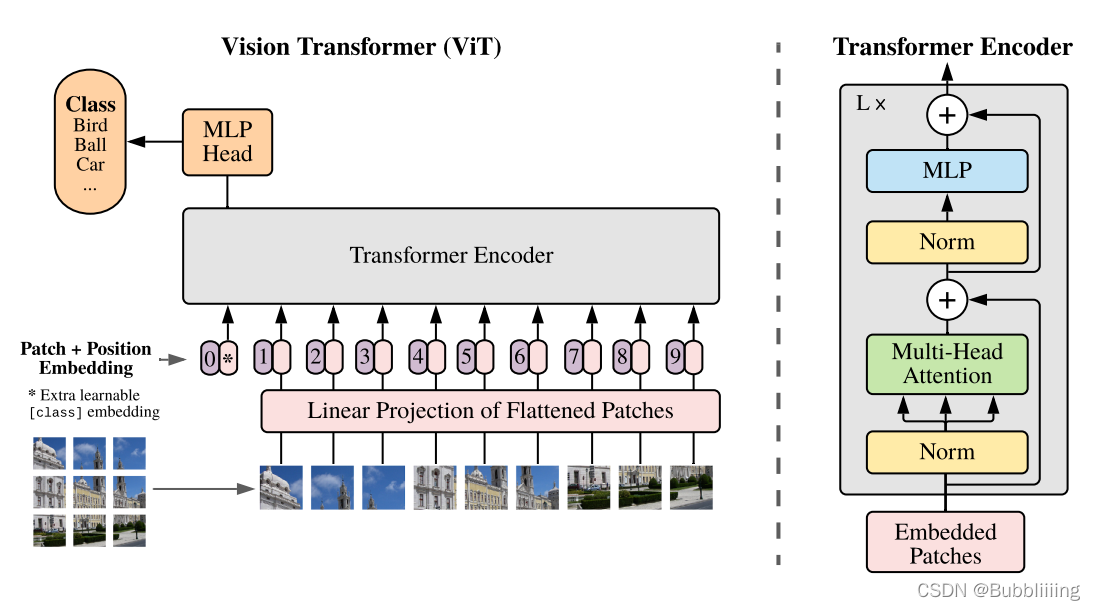
一个Patch+Position Embedding
对输入图像进行卷积,得到的矩阵平铺展开为一个一维向量存储图片的序列信息(mx1)。向量中的每个值代表原图像中的一个卷积核大小的块状区域,代表一个序列单元。当然卷积核会有n个,所有是个mxn的特征矩阵
平铺完成后,我们会在图片序列中添加上Cls Token,该Token会作为一个单位的序列信息一起进行特征提取,图中的这个0*就是Cls Token
添加完成Cls Token后,再为所有特征添加上位置信息,这样网络才有区分不同区域的能力。添加方式其实也非常简单,我们生成一个197, 768的参数矩阵,这个参数矩阵是可训练的,把这个矩阵加上197, 768的特征层即可。
多个Transformer Block
上一步获得的序列信息输入,通过自注意力机制,关注每个块的重要程度。
- Multi-Head Attetion
- 两个连接层
Text Encoder:Bert
和Image Encoder类似
补充:
- Unicode编码几乎可以表示全世界的所有语言字符,常说的ASCII编码是Unicode编码的一个子集。Unicode码点是字符在Unicode字符集中的唯一标识,而UTF-8则是将Unicode码点转换为字节序列的一种编码方式。
- UTF-8是Unicode的一种实现方式,也被称为Unicode转换格式(UTF),是“二进制表示”。它是对Unicode字符集进行编码的一种编码方式,给Unicode字符集加了一个存储类型前缀。
- 有时为了不让字典太大,只会把出现频次大于某个阈值的词丢到字典里边,剩下所有的词都统一编码成#UNK
综合图像和文本特征
$$
min(\sum_{i=1}^N\sum_{j=1}^N (I_i \cdot T_j){i \not= j} - \sum{i=1}^N (I_i \cdot T_i))
$$
得到图像特征和文本特征后,接下来的训练任务转为最大化 N 个正样本的余弦相似度, 最小化$N^2 - N$个负样本的余弦相似度,即最大化对角线中的数值, 最小化其它非对角线的数值



