概念
bbox(Bouding Box边界框):包含物体的最小矩形
NMS(非极大值抑制Non-Maximum Suppression):选出IoU值最高的框,去掉与它的IoU值较高的框(即重复区域较大),然后再选出IoU次大的框,重复上述过程。
two-stage方法:如R-CNN系列算法,其主要思路是先通过启发式方法(selective search)或者 CNN 网络(RPN)产生一系列稀疏的候选框,然后对这些候选框进行分类(classification)与回归(bounding box regression),two-stage方法的优势是准确度高;
one-stage方法:如YOLO和SSD,其主要思路是均匀地在图片多个层数的特征图上进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度快。但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本(背景)极其不均衡,导致模型准确度稍低。
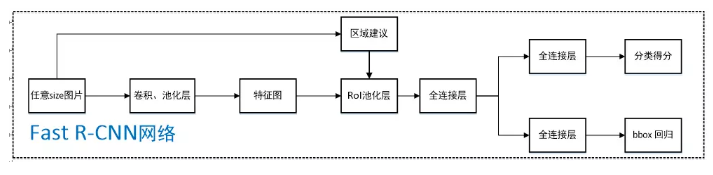
Fast RCNN的改进
| RCNN | Fast RCNN |
|---|---|
| 对一张图片提取了大量候选区域,并把它们都输入到CNN进行特征提取,这些候选区域有大量重复,造成特征提取的浪费 | 将整个图片归一化后直接送入CNN,卷积层不进行候选区的特征提取,在最后一个池化层加入候选区域坐标信息,进行特征提取的计算 |
| 目标分类与候选框的回归是独立的两个操作,并且需要大量特征作为训练样本 | 将目标分类与候选框回归统一到CNN网络中来,不需要额外存储特征 |
结构
Faster RCNN
改进
提出背景:Fast R-CNN通过选择性搜索(selective search)找出所有的候选框,仍然比较耗时
解决方法:加入一个提取边缘的神经网络,把找候选框的工作交给这个神经网络(称作Region Proposal Network,RPN)
具体做法如下:
- 将RPN放在一个卷积层的后面
- RPN直接训练得到候选区域
结构(检测过程)
基本框架如下: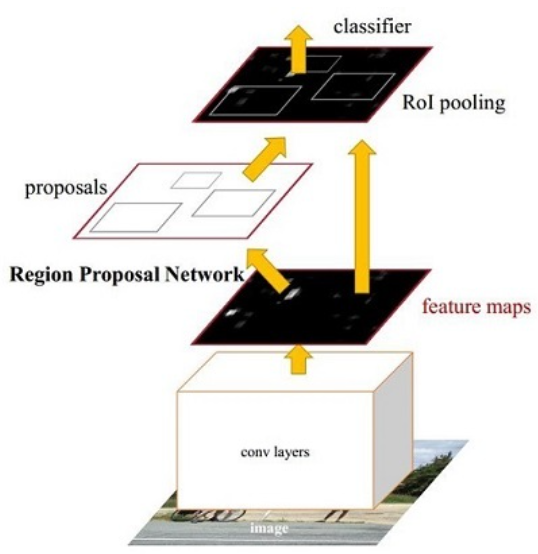
具体结构如下:
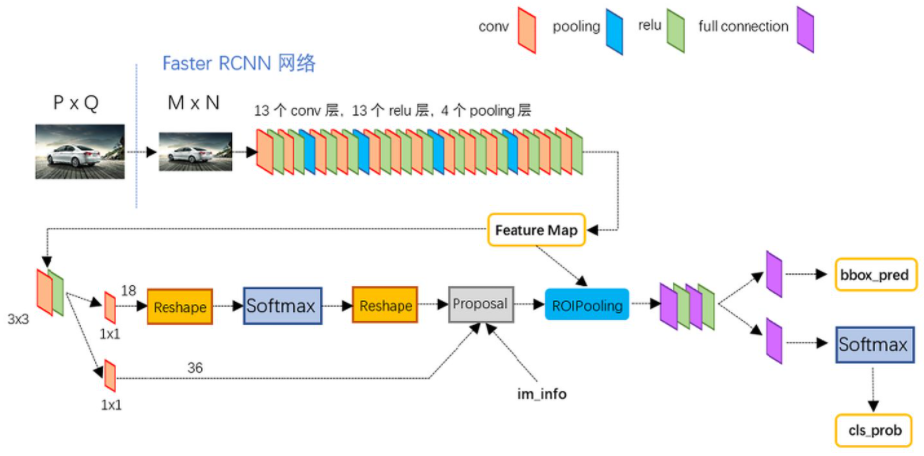
conv layers
特征提取网络,用于提取特征。通过一组conv+relu+pooling层来提取图像的feature maps。
- 13个conv层:kernel_size=3, padding=1, stride=1。因为$n = \frac{n + 2p - f}{s} + 1$,所以经过每个卷积层后feature map维度不变。
- 13个relu层:不改变特征图维度
- 4个pooling层:kernel_size=2, padding=0, stride=2。每池化一次,特征图维度变为原来的1/2,最终变为原来的1/16
RPN
区域候选网络,提前做了一部分检测,完成了目标定位,但还没分出具体类别。流程如下:

拿到conv layers的feature map(M/16 x N/16)后,先经过一个3x3卷积,卷积核个数为256,所以通过这个卷积层后feature map的通道数也是256(M/16 x N/16 x 256)。
之后分成两个任务:
上部分cls layer分类:判断所有预设anchor内是否有目标(二分类),即是正样本(positive)还是负样本(negative)。
补充anchor:对于feature maps的每一个像素点,设置3 x 3种预设anchor,比例3种:1:1、1:2、2:1;边长3种:按原始目标大小灵活设置。这样比例和边长一一配对就可以得到3x3=9种预设锚框。
- 设anchor种类为k(即上文的9个)。M/16 x N/16 x 256的特征经过1x1卷积就得到了(M/16)x(N/16)x2k的输出.“2”是因为这里做的是一个二分类且用的softmax,所以feature map上每个点的每个anchor对应2个值。
- reshape层对feature map进行维度变换,使得有一个单独的维度为2 ,方便在softmax进行操作
- softmax进行分类
- reshape恢复原状
下部分reg layer回归:bbox regression(边界框修正),修正anchors得到较为准确的proposals
(M/16)x(N/16)x256的特征通过1x1卷积得到(M/16)x(N/16)x4k的输出,“4”是因为这里是生成每个anchor的坐标偏移量(用于修正anchor),[tx,ty,tw,th]共4个所以是4k。注意,这里输出的是坐标偏移量,不是坐标本身,要得到修正后的anchor还要用原坐标和这个偏移量运算一下才行。
两个任务在proposal层合并,proposal层负责综合正样本positive anchor和对应bbox修正后得到的proposals,输出一系列proposals左上角和右下角坐标轴,同时剔除太小和超出边界的proposal。
RoI Pooling(兴趣域池化)
收集RPN生成的proposals,并将每个proposal映射到对应feature map中的区域
把这个区域划分成pooled_w x pooled_h个网格
对网格的每部分做max pooling
这么做是因为全连接层每次输入特征的维度必须是相同的。这样保证大小不同的proposal最后输出都是相同大小(pooled_w x pooled_h)。
生成的结果proposals feature maps(pooled_w x pooled_h x 256)送入后续全连接层继续做分类(具体哪一个类别)和回归。
classification and regression
- 利用proposals feature maps计算出具体的类别
- 再做一次bbox regression获得检测框最终的精确位置。
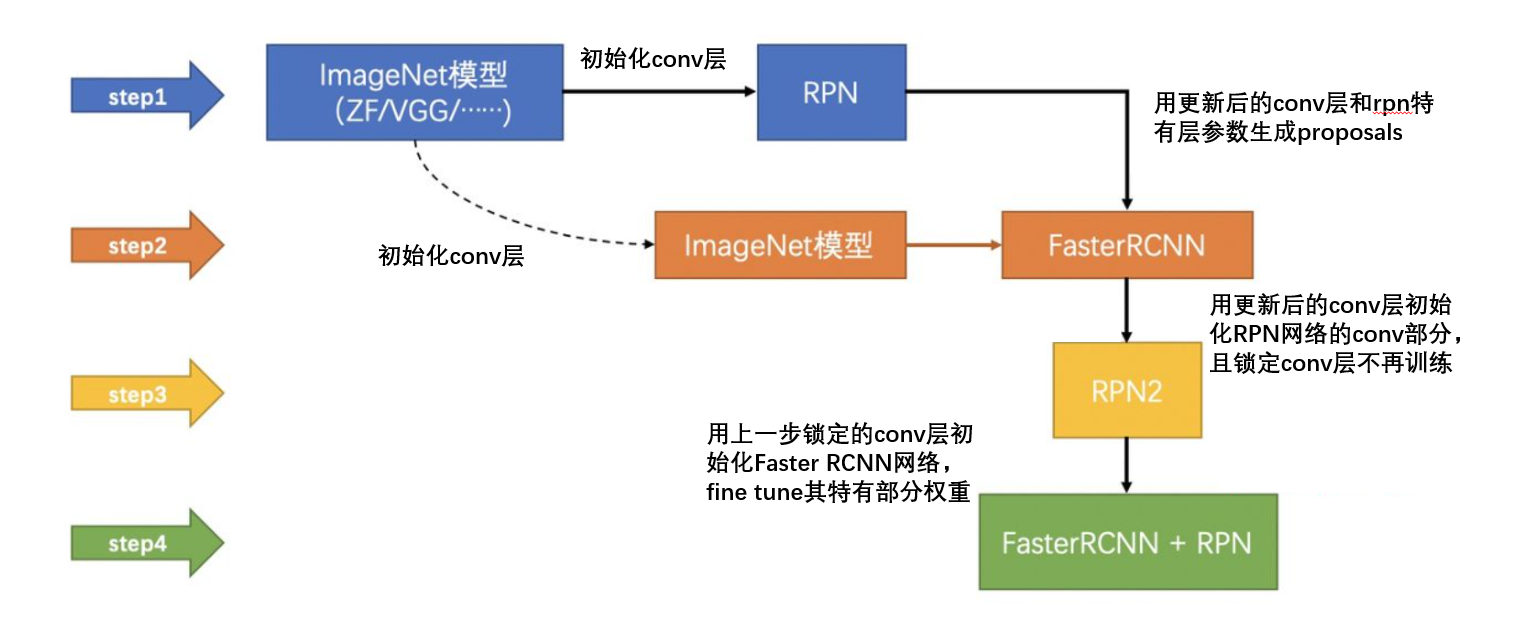
训练过程(two stage)
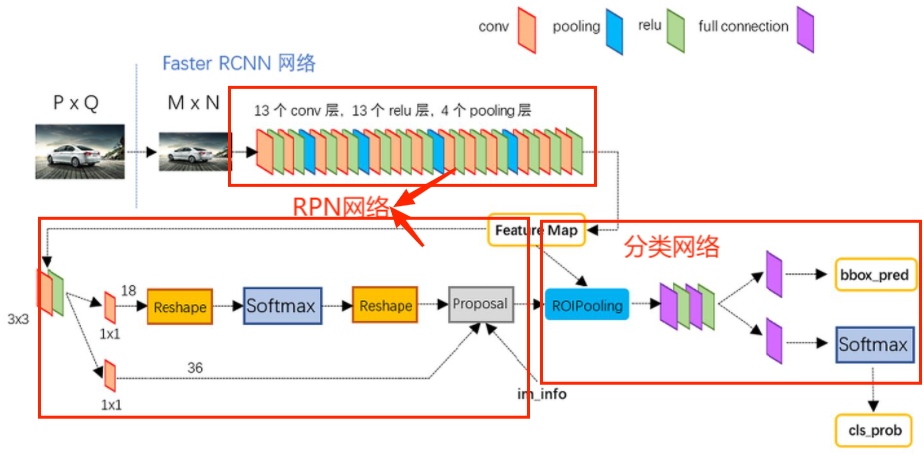
- 训练RPN网络
- 训练分类网络
参考
[超级详细的Faster RCNN解读](一文读懂Faster RCNN - 你再好好想想的文章 - 知乎
https://zhuanlan.zhihu.com/p/31426458)



