yolov5前期配置和运行
注:VOCData文件夹(可以自己命名)下的images和labels文件夹不能叫别的名字!
使用镜像源安装库:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple |
运行train.py的命令
python train.py --weights weights/yolov5s.pt --cfg models/yolov5s.yaml --data data/myvoc.yaml --epoch 200 --batch-size 8 --img 640 --device cpu --resume True |
yolov5项目目录结构理解
- models/yolov5_.yaml:模型的配置文件,有n、s、m、l、x版本,逐渐增大(随着架构的增大,训练时间也是逐渐增大)
- data/hyps/hyp.scratch-_.yaml:超参数配置文件,有low、med、high版本,数据增强效果递增
训练过程
我用git拉取了yolov5源代码(如下图,右边有点点的就是我修改了的文件)
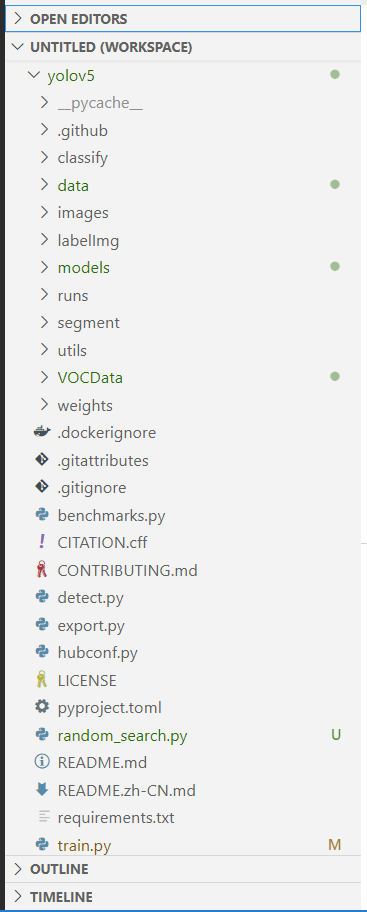
就按这个顺序依次说明
- data文件夹:新建了myvoc.yaml文件
- models文件夹:新建了yolo5s_well.yaml文件,复制了yolo5s里的内容,仅修改了类
- VOCData文件夹:存储自己的数据集,两个py文件顾名思义:用来生成训练集和验证集以及将数据集由xml转化为txt供模型训练
- random_search.py:没有用,可忽略
- train.py:修改了其中的一些参数,主要是路径修改

在九天上我把resume参数default改为true了,这样可以在训练意外中断后,能在之前训练的基础上继续训练,具体做法如下:
- 命令行里输入cd yolov5进入文件夹
- 输入conda activate pytorch激活我配置好的虚拟环境
- 输入nohup python train.py在原来的基础上继续训练,nohup可以把输入放到nohup.txt文件里,保证不在该界面的时候训练依然可以继续(官方文档的ReadMe有写),可以继续训练是因为我改了train.py里的参数,这么输入就可以了
数据增强
yolov5源代码中自带的数据增强方法:需激活
参考资料:YOLOv5-6.x源码分析(七)—- 数据增强之augmentations.py
此篇博客详细介绍了yolov5中使用的数据增强方法,包括:
- 归一化和反规范化
- hsv 色调-饱和度-亮度的图像增强
- 直方图均衡化增强
- 图像框的平移复制增强
- 图片缩放letterbox
- 随机透视变换
- cutout
- mixup
- box_candidates
相关文件:
- utils/augmentations.py
- utils/dataloaders.py
- models/yolov5s_well.py
- data/hyps/hyp.scrath-high.yaml
使用方法(每个方法启用的数据增强不一样)
1. 安装步骤
- 激活虚拟环境:
activate pytorch - 下载库:
pip install albumentations -i https://pypi.tuna.tsinghua.edu.cn/simple
补充说明:
“Albumentations——强大的数据增强库(图像分类、分割、关键点检测、目标检测)”
“YOLOv5集成Albumentations,添加新的数据增强方法”
根据augmentations.py的代码:
class Albumentations: |
可推断必须安装albumentations库才能启动数据增强
T = [ |
这部分可以看到具体应用了哪些数据增强方法
2. hyp.scratch.yaml调整(可启用mixup)
- 方法一:直接用官方的配置文件,将train.py里–hyp参数的默认使用文件修改一下
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="hyperparameters path") |
把这里的hyp.scratch-low.yaml换成hyp.scratch-med.yaml或者hyp.scratch-high.yaml
- 方法二:自己调整hyp.scratch.yaml文件里的参数(不太敢瞎调,或许可以找找文章参考一下别人的?)
**补充说明:**Mixup是指将两张图片和其标签,按权重进行叠加,生成新的数据集和其所对应的标签。
Mixup的步骤如下:
- 从训练数据中随机选择两个样本,记作样本A和样本B。
- 随机选择一个介于0和1之间的权重值λ。
- 将样本A和样本B的特征按照权重值λ进行线性组合:mixed_feature = λ * feature_A + (1 - λ) * feature_B。
- 将样本A和样本B的标签按照权重值λ进行线性组合:mixed_label = λ * label_A + (1 - λ) * label_B。
- 使用mixed_feature作为新的训练样本,使用mixed_label作为对应的标签
3. 启用cutout
把utils/dataloaders.py的被注释掉的cutout部分相关代码取消注释(光标处的下两行)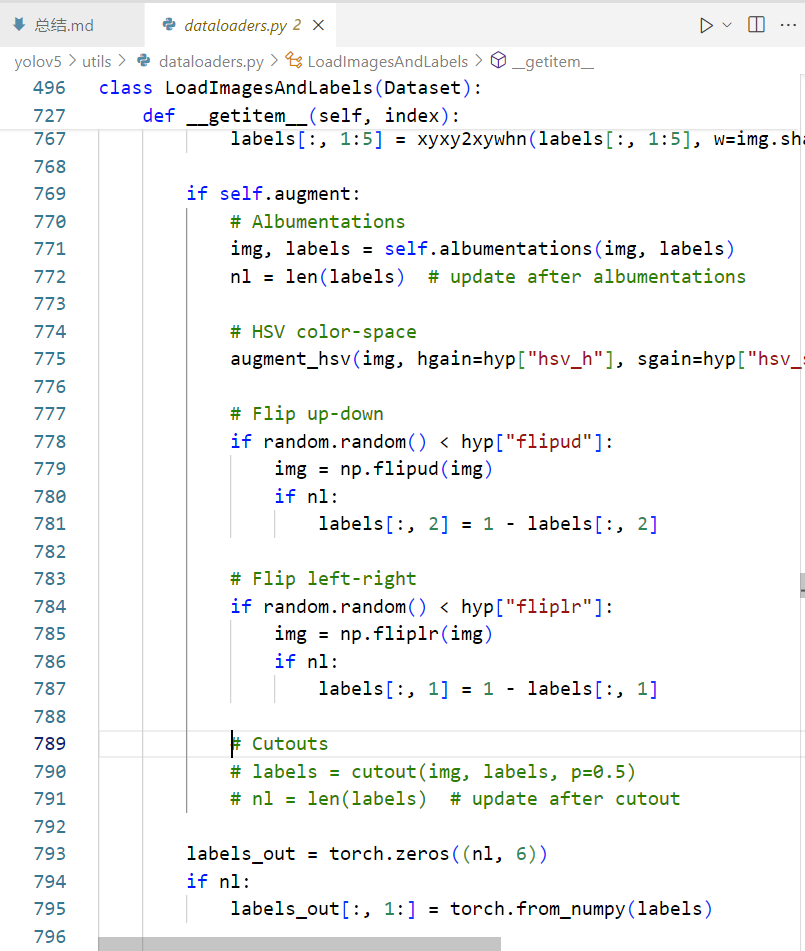
补充说明:
Cutout是指随机的将样本中的部分区域cut掉,并且填充0像素值,分类的结果不变
其他数据增强方法
- Cutmix (参考资料:数据增强方法Mixup、Cutout、CutMix、ClassMix)
Cutmix综合了Mixup和Cutout的想法,把一张图片上的某个随机矩形区域剪裁到另一张图片上生成新图片。标签的处理和mixUp是一样的,都是按照新样本中两个原样本的比例确定新的混合标签的比例。
用自己训练的模型预测/推理
修改detect.py
def parse_opt(): |
weights: 修改为自己训练出的模型,即runs/train/exp/weights目录下的.pt文件
source: 修改为自己想检测的图片集所在的目录
data: 修改为data目录下自己训练时新建的.yaml(里面有训练集、验证集的文件位置和分类信息)
save-txt: 因为我需要把检测结果存为txt文件,所以在这里添加了default=True
save-conf:同样因为检测结果需要输出置信度,所以在这里添加了default=True



