作用
- 决定需要关注输入的哪部分:在处理大量信息时,注意力机制能够帮助模型或个体确定哪些部分是重要的,并集中资源进行处理。例如,在机器翻译任务中,注意力机制可以帮助模型确定源语言句子中哪些词汇对目标语言的翻译更为重要。
- 分配有限的信息处理资源给重要的部分:通过给重要的信息部分分配更多的注意力,模型可以更有效地利用资源,从而提高处理效率和准确性,解决信息过载问题。这类似于人类视觉注意力机制,通过快速扫描全局图像,获得需要重点关注的目标区域,然后对这一区域投入更多注意力资源,以获取更多细节信息,同时抑制其他无用信息。
概念
- 查询向量Query:指的是查询的范围,自主提示,即主观意识的特征向量
- 键向量Key:指的是被比对的项,非自主提示,即物体的突出特征信息向量
- 值向量Value:物体本身的特征向量,通常和Key成对出现
具体过程
对于每一个Query,计算所有Key与它的相关性,然后根据这个相关性去找对应的Value(Key、Value成对出现),Query和Key相关性高的其对应Value要重点关注(分配更高的注意力权重)。
计算Key与Query的相关性
$$
scores_i = Query \cdot Key_i
$$
softmax进行归一化,得到权重系数
$$
\alpha_i = softmax(scores_i) = \frac{e^{scores_i}}{\sum_{j=1}^{Lx} e^{scores_j}}
$$
对Value进行加权求和,得到Attetion Value
$$
Attetion = \sum_{i=1}^{Lx} \alpha_i \cdot Value_i
$$
自注意力机制
提出背景:输入向量大小不一,并且不同向量之间有一定的关系,但是实际训练的时候无法充分发挥这些输入之间的关系,导致模型训练结果效果不好。
特色:让机器注意到整个输入中不同部分之间的相关性。是一组元素内部相互做注意力机制,因此自注意力机制也叫做内部注意力机制。
实现过程:Q、K、V是同一个东西,或者三者来源于同一个输入X。
- 对于每一个输入向量X,分别乘上系数$W^q、W^k、W^v$(需要学习的参数),得到Q、K、V。
- 利用Q和K计算每两个输入向量之间的相关性(scores),一般采用点积计算
- 用softmax归一化,得到注意力权重
- 用权重乘每个Value,最终得到输出向量Z
# 自注意力机制 |
缺点:
- 自注意力机制过滤了不重要的信息,会导致模型有效信息的抓取能力比CNN弱,因为模型无法利用图像本身具有的尺度、平移不变性以及图像的特征局部性这些先验知识,只能通过大量数据进行学习。所以一般自注意力机制在大数据的基础上才能有效地建立准确的全局关系,而在小数据的情况下可能效果不如CNN。
- 没有考虑向量的位置信息
多头注意力机制
提出背景:使用自注意力机制的模型,对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置,有效信息抓取能力变差。
特色:用独立学习得到的h组(一般h=8)不同的线性投影(linear projections)来变换Q、K、V。 然后,这h组变换后的Q、K、V将并行地送到注意力汇聚中。 最后,将这h个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。
实现过程:
- 对于一个输入向量X,将它拆分成h组,并定义多组W:$W_0^q、W_0^k、W_0^v…W_7^q、W_7^k、W_7^v$
- 每组都按上述自注意力机制实现过程走一遍,得到多个输出$Z_0…Z_7$
- 将多个输出拼接后乘以一个矩阵转化为跟输入X相同的维度
通道注意力机制
提出背景:之前都是关注图片不同位置的重要性,而图片的另一个维度就是通道,所有也可以计算不同通道的重要性。
CA(coordinate attettion)注意力机制
提出背景:现有的注意力机制在求取通道注意力的时候,一般采用的全局最大池化/平均池化,这样会造成物体空间信息的损失。
特色:在引入通道注意力机制的同时,引入空间注意力机制。
实现过程:将位置信息嵌入到通道注意力中
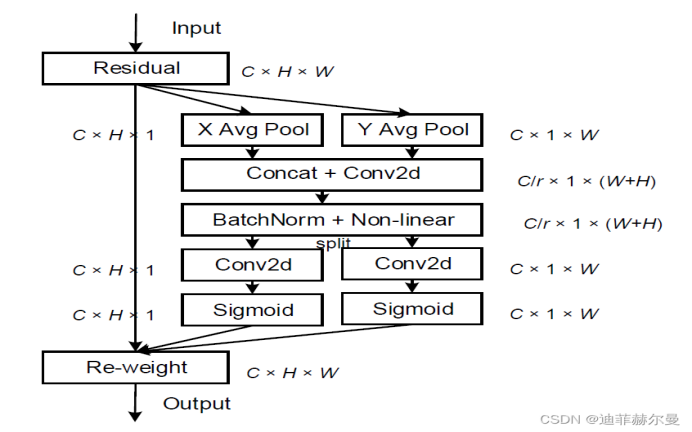
CA注意力机制分为两个并行阶段。
- 首先将输入特征图(CxHxW)分别在宽度、高度两个方向进行全局平均池化,获得在宽度、高度两个方向的特征图(Cx1xH、CxWx1)。
- 将两个并行阶段合并,将宽和高转置到同一个维度,然后堆叠,将宽高特征合并得到特征层C x 1 x (H+W)
- 利用卷积+标准化+激活函数获得特征
- 再次分开为两个并行阶段:Cx1xH、CxWx1
- 利用1x1卷积调整通道数后取sigmoid获得宽、高维度上的注意力情况,扩展成CxHxW矩阵,乘上原有的特征图



